Hugging Face 上下载模型的时候,你可能见过这样的命名:Llama-3-8B-Q4_K_M、Qwen-32B-GPTQ-Int4。那个 Q4、Int8 到底是什么意思?为什么同一个模型会有这么多不同的”版本”?更关键的问题是——用了这些”缩水版”模型之后,回答的质量会不会塌掉?
今天就来聊聊这件事。
先说一个直觉
大语言模型的本质,是一大堆数字。比如一个 70 亿参数的模型,里面就有 70 亿个”权重”——可以理解为 70 亿个小旋钮,每个旋钮都精确到小数点后十几位。模型训练完成后,这些旋钮的数值就固定了,它们共同决定了模型”怎么想问题”。
默认情况下,每个权重用 32 位浮点数(FP32)来存储——这就意味着每个数字占 4 个字节。70 亿个参数,光是权重文件就大约 28GB。如果是 700 亿参数的模型呢?280GB。你家里的 RTX 4090 只有 24GB 显存,连塞都塞不进去。
所以问题就来了:有没有办法,把这些数字存得更粗糙一点,但又不太影响模型的表现?
这就是量化(Quantization)。
量化到底在干什么
量化的核心思路其实很朴素:把高精度的数字,压缩成低精度的数字。
打个比方。假设你有一本百科全书,里面每个数据都精确到小数点后 16 位:圆周率写成 3.1415926535897932。量化做的事情就像是——把它四舍五入成 3.14,甚至直接写成 3。你损失了一点精度,但省下了大量的存储空间和计算量。
具体到技术细节,常见的量化精度有这么几档:
- FP32(32 位浮点):全精度,训练时的默认格式。大、慢、准。
- FP16 / BF16(16 位浮点):半精度。模型体积减半,准确率几乎无损。目前推理的主流基线。
- INT8(8 位整数):模型体积是 FP32 的四分之一。这是目前生产环境部署最稳妥的选择。
- INT4(4 位整数):模型体积是 FP32 的八分之一。非常激进的压缩方案,但能让大模型跑在消费级显卡上。
每降一档,模型就更小、更快。但代价是——你能表达的数值范围更窄了,精度更低了,潜在的”量化误差”也更大了。
那质量到底掉多少?
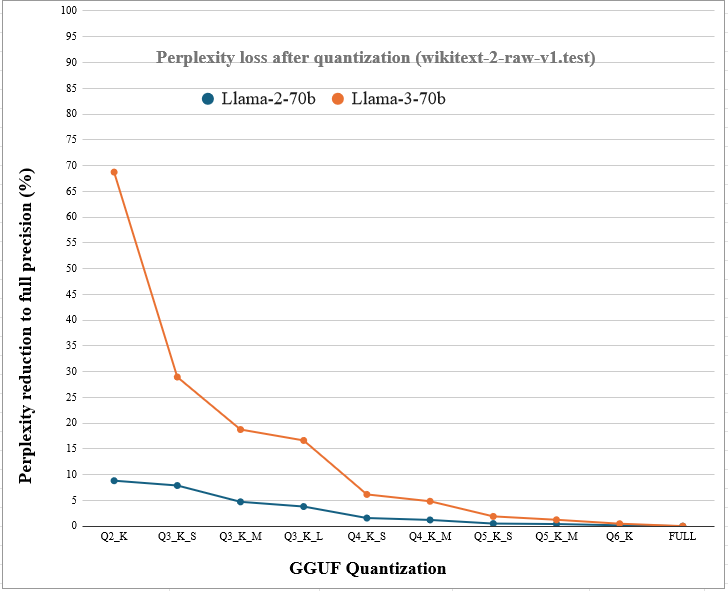
这是所有人最关心的问题。说实话,答案可能比你想象的乐观得多。
先看 INT8。在多项基准测试中,INT8 量化带来的准确率下降小得几乎可以忽略。有研究在 Llama-3.1 系列模型上做了系统测试,发现 INT8 权重加激活量化(W8A8-INT)相比全精度,准确率通常只掉 1% 到 3%。而在一项针对 Qwen3-32B 的实测中,INT8 相比 BF16 的性能差异只有 0.04%——这个数字基本就是统计噪声。
换句话说,INT8 对绝大多数任务来说,几乎是”无损”的。这也是为什么它被广泛认为是生产环境的稳妥之选。
再看 INT4。这个就有意思了。直觉上你会觉得,把 16 位的数字硬塞进 4 位,肯定损失惨重。但现代的量化算法(比如 GPTQ、AWQ)并不是傻乎乎地直接截断,而是通过校准数据、分组量化、重要通道保护等一系列手段来最小化信息损失。结果是:在同一个 Qwen3-32B 测试中,INT4 量化的模型在 MMLU-Pro 基准上保留了 98.1% 的基线推理能力。而 QLoRA 的研究更是表明,4 位量化的模型能够保留约 99% 的原始性能。
当然,INT4 并不是万能的。如果你的应用场景涉及复杂推理、代码生成、或者需要处理很长的上下文,INT4 模型更容易出现质量漂移——回答变得更干巴、更模式化,偶尔推理链会断裂。这类任务对精度更敏感,INT4 的”毛刺”会更明显。
而 3 位、2 位量化目前还处于研究阶段,质量下降就比较显著了,不建议在正式场景中使用。
为什么不直接训练的时候就用低精度?
你可能会问:既然低精度这么好,为什么不一开始就用 INT8 训练?
因为训练和推理对精度的要求完全不同。训练过程中,梯度更新非常微妙,优化器的状态有着极宽的动态范围。如果训练时精度太低,梯度会变得嘈杂不堪,模型根本收敛不了。所以训练一般都在 FP32 或 BF16 下进行,等模型训练完了,再做量化。
这就是所谓”训练后量化”(Post-Training Quantization, PTQ)的思路——先正常训练,然后把”成品”压缩。它简单、快速,不需要重新训练,是目前最普遍的做法。
还有一种更高级的路线叫”量化感知训练”(Quantization-Aware Training, QAT)——在训练过程中就模拟量化的效果,让模型提前适应低精度带来的误差。这种方法的精度保留更好,但成本也更高,需要更多的计算资源和时间。
主流量化方法:条条大路通罗马
知道了”量化是什么”和”什么时候量化”之后,下一个自然而然的问题就是——具体怎么量化?
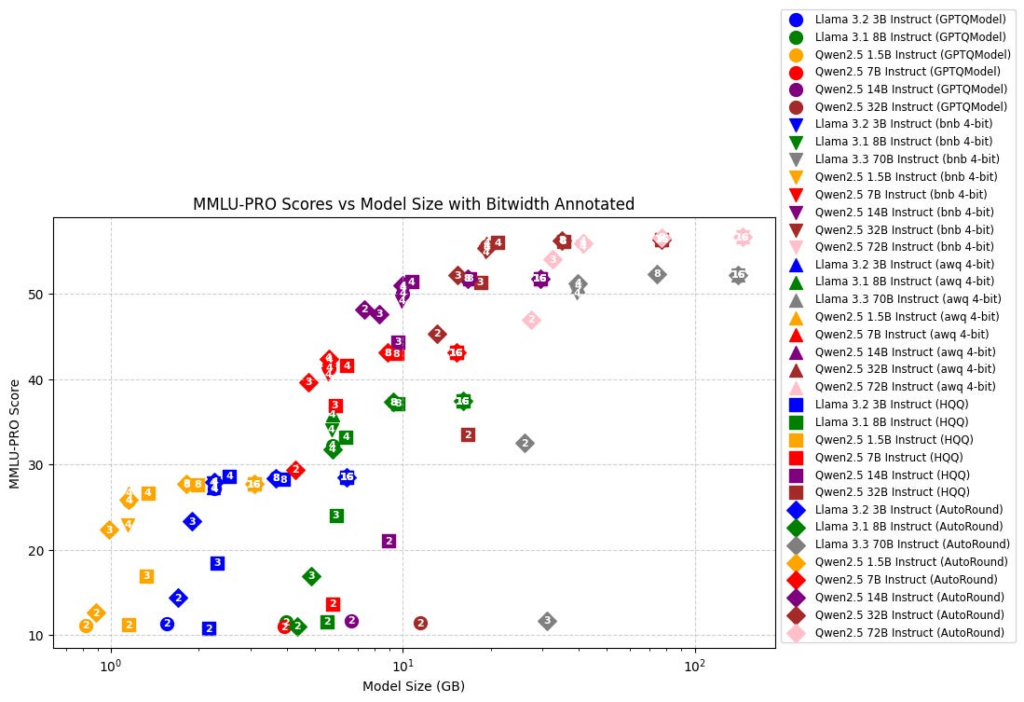
你在下载模型的时候,经常会看到文件名里挂着 GPTQ、AWQ、GGUF 这些缩写。它们不是精度等级,而是不同的量化算法和格式。每种方法的思路不同,擅长的场景也不一样。这里逐个聊聊。
GPTQ:元老级选手
GPTQ 大概是最早被广泛使用的大模型量化方法之一。它的全名叫”Accurate Post-Training Quantization for Generative Pre-trained Transformers”,一听就知道是专门为 GPT 类模型设计的训练后量化方案。
它的核心思路是:利用近似的二阶信息(也就是 Hessian 矩阵)来指导量化过程。简单来说,它不是一股脑把所有权重都粗暴地四舍五入,而是一列一列地处理权重矩阵——每量化一列,就去补偿这一列的舍入误差对后续列的影响。这种”逐列量化 + 误差补偿”的策略,让它在 4 位甚至 3 位精度下都能保持不错的质量。
GPTQ 的生态非常成熟。AutoGPTQ 工具库让量化过程几乎是一键式的,Hugging Face Transformers 也原生集成了对 GPTQ 模型的支持。如果你在 Hugging Face 上看到模型名字里带 GPTQ-Int4,大概率就是用这个方法量化的。
不过 GPTQ 的一个特点是——它是纯 GPU 方案。量化后的模型需要整个放进显存里跑,不支持 CPU 卸载。如果你的显存刚好够,它跑得飞快;如果不够,那就只能换方案了。
AWQ:更聪明的”看人下菜碟”
AWQ 的全名是 Activation-aware Weight Quantization,”激活感知”的权重量化。它的核心洞察很简洁:不是所有的权重都一样重要。
具体来说,AWQ 会先跑一批真实数据通过模型,观察哪些权重通道对应的激活值特别大。激活值大,意味着这个通道对模型输出影响很大——这些就是”关键通道”。然后在量化的时候,AWQ 会给这些关键通道分配更高的精度,保护它们不被量化误差破坏。
这个思路有点像考试划重点:你的时间有限(比特数有限),不可能每个知识点都复习到位,那就优先保住分值最高的题目。
实际效果上,AWQ 在相同比特数下通常比 GPTQ 能获得稍好一点的输出质量,尤其是在 4 位量化这种激进压缩下。很多聊天模型的 AWQ 版本在社区里口碑不错。它同样是纯 GPU 方案,并且在配合 Marlin 这样的优化推理内核时,速度表现非常亮眼。
GGUF:本地玩家的最爱
如果你用过 llama.cpp、Ollama 或者 LM Studio,那你一定接触过 GGUF 格式。它是 GGML 的继任者,也是目前本地部署大模型最流行的格式之一。
GGUF 最大的特点是灵活的 CPU/GPU 混合推理。它允许你把模型的一部分层放在 GPU 显存里,另一部分卸载到系统内存(RAM)上由 CPU 处理。这意味着即使你的显存装不下整个模型,只要内存够大,模型照样能跑——只是速度会慢一些。
GGUF 支持非常丰富的量化等级,你在文件名里看到的 Q2_K、Q3_K_M、Q4_K_M、Q5_K_M、Q6_K、Q8_0 这些就是不同的量化档位。特别值得一提的是那些带”K”的变体(k-quant 方法),它们并不是对所有权重一视同仁地量化到相同比特数,而是对模型中不同类型的张量分配不同的精度。比如 Q4_K_M 的平均精度大约是 4.5 比特而不是整 4 比特,因为它会给更敏感的张量多留一些精度余量。
如果你是在自己的笔记本或台式机上玩模型,显存不够用,又想尽可能体验大参数模型的效果,GGUF 基本就是你的首选。
bitsandbytes(LLM.int8):最低门槛的入口
bitsandbytes 库是 Tim Dettmers 的代表作,也是很多人接触量化的第一站。它最出名的功能是 LLM.int8()——一种特别聪明的 8 位量化方案。
大模型权重中有一个棘手的问题:激活值中偶尔会出现数值特别大的”离群值”(outlier)。如果你用统一的缩放因子去量化,这些离群值要么被截断(损失信息),要么把缩放因子撑得很大(导致其他正常值的精度变差)。LLM.int8() 的做法是:把包含离群值的通道单独挑出来,用 FP16 精度处理,其余的正常通道用 INT8。这种”混合精度”的思路,让 8 位量化在几乎不损失精度的前提下变得非常可靠。
bitsandbytes 还支持 4 位量化,其中 NF4(NormalFloat4)格式是一个亮点。它的设计基于一个观察:神经网络的权重分布通常近似正态分布。NF4 的量化级别就是按照正态分布来优化的,所以对这类权重能获得比普通 INT4 更好的精度。QLoRA 微调方案用的就是这个格式。
bitsandbytes 的最大优势是简单——加载模型时传一个参数就行,几乎零配置。缺点是推理速度不算最快,更适合做实验和微调,不太适合高吞吐的生产部署。
SmoothQuant:先”削峰”再量化
SmoothQuant 的切入角度很有趣。它不直接改变量化算法本身,而是在量化之前先对数据做一次预处理。
前面提到,激活值中的离群值是量化的大敌。SmoothQuant 的思路是:既然激活值有尖峰,那我就把尖峰”平滑”掉。具体做法是通过一个数学上等价的线性变换,把激活值中的大幅波动”转移”一部分到权重上去。变换之后,激活值的分布变得更平缓了,量化起来也就容易多了。
这个方法特别适合那些激活值波动特别大的模型(比如早期的 OPT、BLOOM 系列),能在 INT8 精度下实现接近无损的效果。它通常作为一个预处理步骤,可以和 PTQ 方法配合使用。
EXL2:精度的精细调控
EXL2 是 ExLlamaV2 项目的量化格式,它的独到之处在于逐层可变比特率。
大多数量化方法对整个模型施加统一的比特数——比如全部 4 比特或全部 8 比特。但模型的不同层对量化的敏感度其实差异很大。EXL2 会分析每一层的敏感度,然后自动给敏感层分配更多比特,给不敏感层分配更少比特。最终的平均比特数可能还是 4 点几,但质量却比统一 4 位要好不少。
当整个模型能完全装进 GPU 显存时,EXL2 是速度和质量兼顾的优秀选择。不过它的生态相对小众一些,主要在 ExLlamaV2 推理引擎内使用。
小结一下
量化方法这么多,选哪个?一条简单的经验:如果你用 GPU 跑推理、追求速度——AWQ 或 GPTQ 配合 Marlin 内核是主流选择;如果你显存不够需要 CPU 卸载——GGUF 几乎是唯一的路;如果你想快速实验或做微调——bitsandbytes 最省心;如果你想在有限比特数下榨取最高质量——EXL2 值得一试。
归根结底,没有”最好”的量化方法,只有最适合你的硬件和场景的那一个。
现实世界中意味着什么
说点实际的。
一个 70B 参数的模型,如果用 FP16 存储,权重文件大约 140GB。你需要两块 A100 80GB 才能装下它。但如果做 INT4 量化呢?权重缩减到大约 35-40GB,一块消费级的 RTX 4090(24GB 显存)配合一些 CPU 内存卸载,就能跑起来。
速度方面,INT4 量化能带来接近 2.7 倍的吞吐量提升。模型变小了,GPU 从显存搬运数据的时间变短了,计算单元等待数据的时间也变短了——因为大模型推理的瓶颈通常不在算力,而在显存带宽。
成本方面也很可观。有估算显示,从 BF16 切换到 INT4,硬件成本可以降低约 63%。如果你每月处理上亿 token,每张 GPU 能省下一千多美元。
那我该怎么选?
这里给一个简单的决策框架:
如果你追求最高质量、不差钱不差卡——用 FP16 或 BF16,没什么好说的。
如果你想在几乎不损失质量的前提下省一半显存——用 INT8。它是目前公认最稳的”生产级”量化方案,硬件支持好,几乎所有主流推理框架(vLLM、TensorRT-LLM 等)都原生支持。
如果你的显存实在不够、或者想让大模型跑在消费级硬件上——试试 INT4。但建议你在自己的实际任务上做一轮评估,特别关注长文本、数学、代码这类对精度敏感的场景。一个常用的经验法则是:如果 INT4 能带来 1.6 倍以上的吞吐提升,同时任务得分只掉 1-2%,那就放心用。
还有一种折中策略越来越流行——混合精度量化。比如注意力层用 FP8,前馈层用 INT4;或者对量化更敏感的层分配更多比特,不敏感的层压得更狠。EXL2 这样的格式就支持逐层分配不同的精度,在同等平均比特数下能获得更好的质量。
写在最后
量化是一门”精打细算”的艺术。它不是简单的”压缩”或”降质”,而是在存储空间、计算速度和输出质量之间寻找最佳平衡点。
好消息是,随着 GPTQ、AWQ、SmoothQuant 这些越来越聪明的量化算法出现,”低精度”和”高质量”之间的鸿沟正在被快速填平。INT8 已经是几乎无损的了,INT4 在大多数日常任务中也表现得出人意料地好。
如果你正在本地跑模型,或者在考虑怎么降低部署成本,量化几乎是你绕不开的第一步。不必害怕它——那些被四舍五入掉的小数点后十几位,大概率不会影响模型给你写的那封邮件或者回答你的那个编程问题。
真正重要的不是每个数字有多精确,而是这些数字组合在一起,依然能让模型”思考”。
发表回复