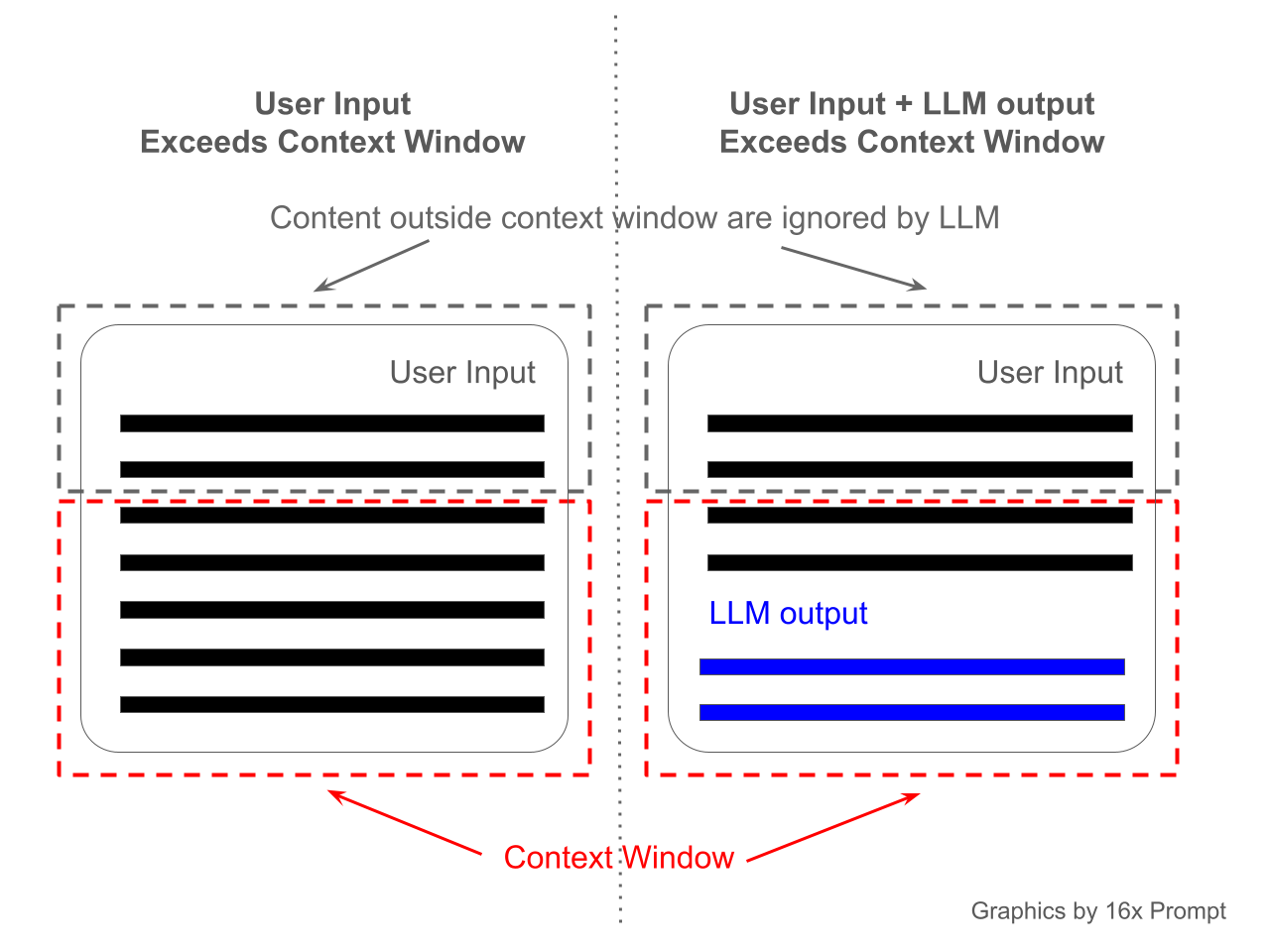
用过 ChatGPT 或 Claude 等大语言模型的朋友大概都碰到过这种场景:聊着聊着,模型突然开始”失忆”,前面说过的话好像全忘了。或者你想把一整本书扔进去让它帮你总结,它告诉你:太长了,放不下。
这就是上下文窗口(Context Window)在起作用。它是 LLM 的”工作记忆”,决定了模型在一次对话中最多能”看到”多少文字。早期的 GPT-3.5 只有 4096 个 token 的窗口(大约 3000 个英文单词),到今天 Google 的 Gemini 已经能处理 200 万 token。听起来进步巨大,但上下文窗口的限制从未真正消失过。
那问题来了:为什么会有这个限制?是硬件不够强?还是算法本身有天花板?答案是——两者都有,而且远比你想的复杂。
一切要从自注意力机制说起

LLM 之所以能理解语言,核心依赖一个叫做”自注意力”(Self-Attention)的机制。简单说,模型在处理每一个词(token)的时候,需要去”看”输入中的每一个其他词,计算它们之间的关联程度。这个过程有点像你在读一篇文章时,读到某个代词”他”,你的大脑会自动回溯去找”他”到底指的是谁。
这个机制非常强大,但有一个致命的代价:它的计算复杂度是 O(n²)。
n 是输入序列的长度(token 数量)。当你把输入长度翻一倍,计算量不是翻一倍,而是翻四倍。10000 个 token 需要 1 亿次比较运算,100000 个 token 就变成了 100 亿次。这种平方级别的增长,意味着上下文长度每往上推一点,背后需要付出的算力成本就呈爆炸式增长。
所以当你看到某个模型宣称支持 128K 甚至百万级别的上下文窗口时,你要知道,支撑这个数字的不仅仅是一个简单的参数调整,而是背后庞大的工程优化和硬件投入。
KV 缓存:越聊越慢的真正原因
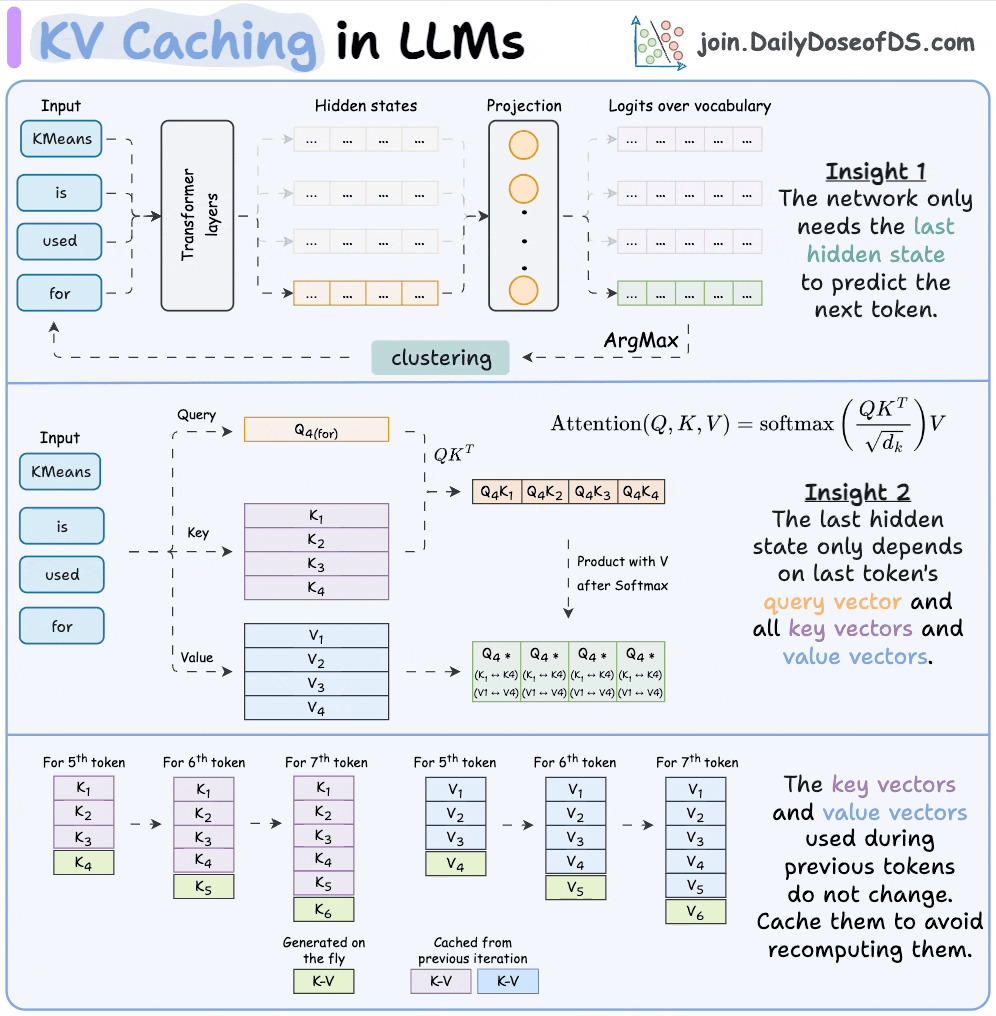
理解了自注意力机制的二次复杂度之后,还有一个更实际的瓶颈需要了解:KV 缓存(Key-Value Cache)。
LLM 在生成文本的时候是逐字逐句来的——每次只输出一个 token。为了避免每生成一个新词就把整段对话从头算一遍(那效率实在太低了),模型会把之前计算过的中间结果(所谓的 Key 和 Value 向量)存下来,放在一个缓存里。下次生成新 token 时,直接复用这些缓存,只需要计算新 token 和所有旧 token 的关系就行了。
这个缓存机制极大地提升了推理速度,但它有一个很现实的问题:缓存会随着对话长度线性增长,而且每一层 Transformer、每一个注意力头都要维护自己的一份缓存。
对于一个大型模型来说,KV 缓存的大小取决于好几个因素:模型的层数、注意力头的数量、隐藏维度的大小、当前序列的长度,以及同时处理的请求数量。这些因素叠加在一起,缓存的显存(GPU 的内存)占用会非常惊人。一个 70B 参数的模型,在处理几万 token 的上下文时,光 KV 缓存就可能吃掉几十 GB 的显存。
这就是为什么你跟 AI 聊久了之后,会明显感觉到回复变慢——每生成一个新 token,模型都需要从显存里把越来越长的 KV 缓存读出来做计算。GPU 的运算速度其实够快,真正的瓶颈在于数据搬运。现代 GPU 拥有极强的浮点运算能力,但显存带宽是有上限的。当模型需要反复把巨大的 KV 缓存在高速显存(SRAM)和主显存(HBM)之间来回搬运时,GPU 大部分时间实际上在等数据,而不是在做计算。
位置编码:模型的”方向感”也有极限
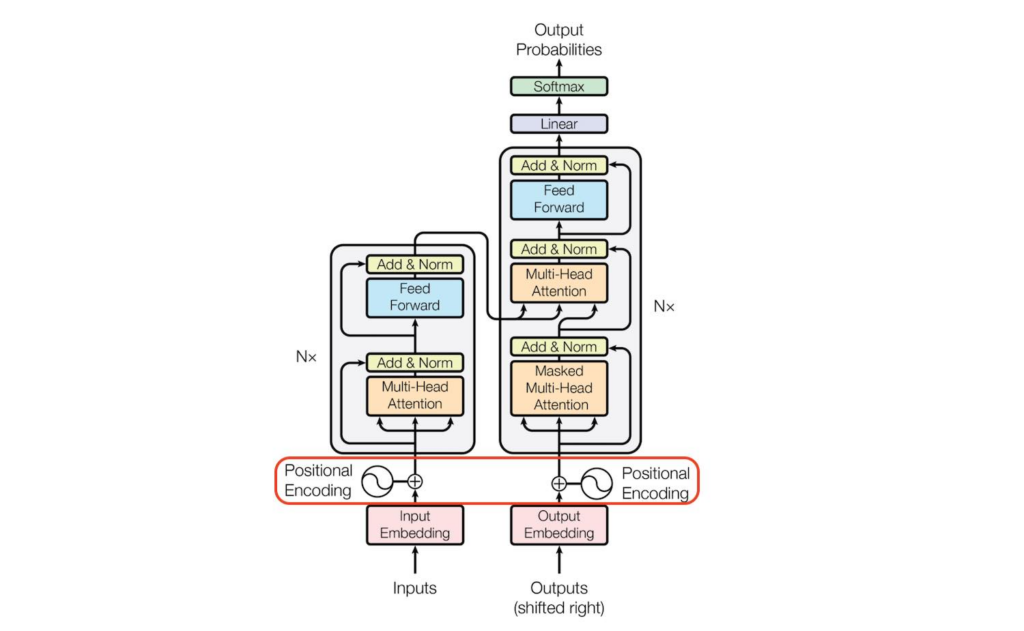
Transformer 架构有一个常被忽略的特性:它本身其实不关心输入的顺序。对 Transformer 来说,”猫追狗”和”狗追猫”如果没有额外的位置信息,看起来是一样的。所以模型需要一种叫”位置编码”(Positional Encoding)的机制来告诉它每个 token 在序列中的位置。
早期的模型用的是固定的正弦位置编码,后来主流方案变成了旋转位置编码(RoPE),被 LLaMA、GPT 系列等广泛采用。RoPE 的聪明之处在于,它编码的是 token 之间的相对位置关系,而不是绝对位置。理论上这应该更容易泛化到更长的序列。
但实际效果并没有那么理想。一个在 4096 token 上训练的模型,如果你直接给它塞 100000 个 token,它会遇到训练时从未见过的位置索引。这就像让一个只练过跑 400 米的人突然去跑马拉松——虽然基本动作是会的,但后半程的节奏完全不在训练范围内,表现会急剧下降。研究表明,RoPE 在处理远超训练长度的序列时,注意力分数可能出现严重退化,甚至产生不稳定的数值结果。
为了解决这个问题,研究者们想了各种办法:位置插值(Position Interpolation)把长序列的位置”压缩”进原来的训练范围内,NTK-aware 插值调整了旋转频率的分布,LongRoPE 则通过两步法(先在中等长度上微调,再做位置插值)把上下文扩展到了 200 万 token 的量级。这些方法确实有效,但它们更像是补丁,而不是根本解法。本质上,位置编码的泛化能力是受限的——模型需要在足够长的序列上训练过,才能真正理解长距离的位置关系。
训练成本:一道绕不过去的经济学题
即使硬件和算法都能支持,还有一个现实问题:训练一个拥有超长上下文窗口的模型需要多少钱?
前面说了,自注意力的计算量随序列长度呈平方增长。这意味着,同一个模型,在 8K 上下文长度上训练,自注意力层的计算量大约是 2K 上下文的 16 倍。如果要训练 128K 的上下文,相比 4K 就是大约 1024 倍的计算量。
大模型本身的训练已经极其昂贵,再乘上这个倍数,成本就完全不在同一个量级了。这就是为什么历史上那些最大的模型往往没有最长的上下文——两者同时做到在经济上几乎不可行。研究者通常需要在模型大小和上下文长度之间做取舍,或者采用一些折中策略,比如先在短序列上训练,然后在较长序列上做少量微调来扩展上下文能力。
另外,高质量的长文本训练数据本身也是稀缺资源。互联网上的大部分文本其实都不长,真正有意义的、连贯的超长文档(比如完整的书籍、法律合同、代码库)的数量远少于短文本。研究已经表明,在预训练阶段混入足够的长文档对于模型学习长上下文能力至关重要,但收集和整理这些数据本身就是一项工程挑战。
“中间迷失”:有了大窗口,模型就真的能用好吗?
这是一个很多人忽略但极其重要的问题。即使上下文窗口足够大,模型也不一定能有效利用里面的所有信息。
2023 年,斯坦福大学的 Nelson Liu 等人发表了一篇很有影响力的论文,标题叫 “Lost in the Middle”。他们的实验发现,LLM 对上下文中信息的利用能力呈现出一个明显的 U 型曲线:放在开头和结尾的信息,模型用得最好;而放在中间的信息,模型经常”视而不见“。
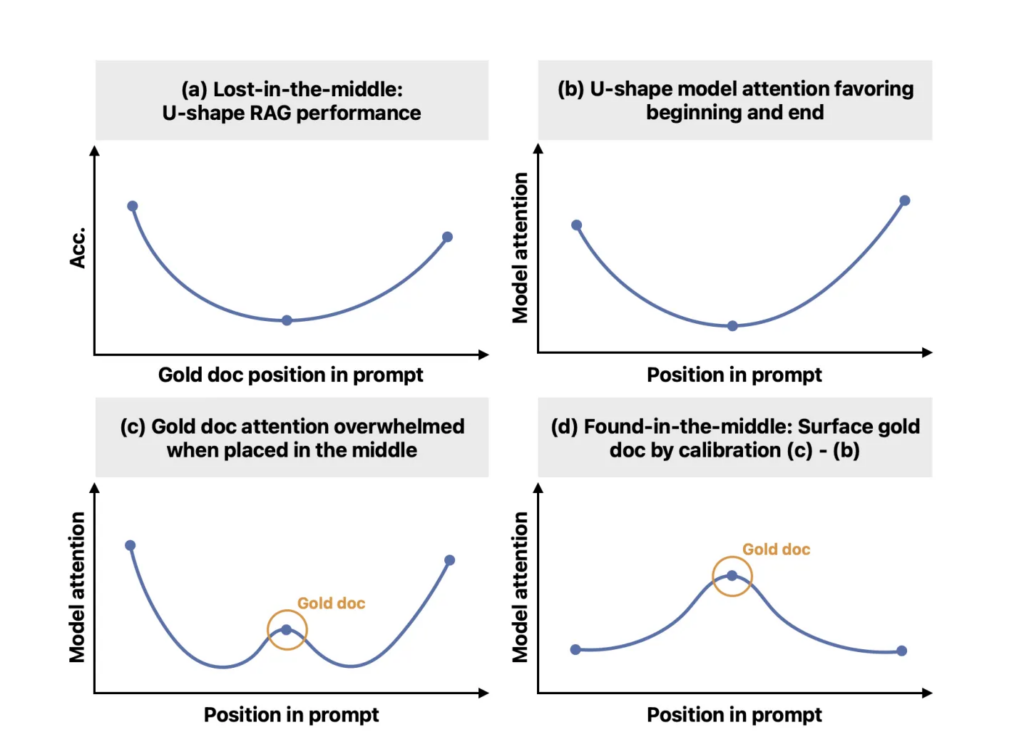
这意味着,一个声称拥有 100 万 token 上下文窗口的模型,当你把关键信息放在第 50 万个 token 的位置时,它可能完全忽略掉。窗口大小只是一个上限,真正决定模型表现的是它对上下文信息的有效利用率。100 万 token 的窗口,在使用体验上并不等于 100 万 token 的完美记忆。
这个现象的原因可能和注意力分数的分布有关——随着序列变长,注意力会被”稀释”,中间位置的信息更容易被模型的注意力机制跳过。也可能和训练数据的分布有关——在自然语言中,前文和最近的上文通常确实比中间的内容更重要,模型在训练过程中学会了这种偏好。
所以现在行业内越来越多的共识是:上下文工程(Context Engineering)比一味地增大窗口更重要。 精心选择放进上下文的内容、控制信息的位置和密度、用 RAG(检索增强生成)来动态获取相关信息,往往比简单地把所有东西一股脑塞进一个巨大的窗口效果更好。
一场多维度的博弈
回头来看,上下文窗口的限制从来都不是单一因素造成的。它是一场涉及数学、硬件、工程和经济学的多维博弈:
自注意力的 O(n²) 复杂度设定了计算成本的基本增长曲线。KV 缓存的显存占用决定了推理时的实际天花板。GPU 的显存带宽限制了每个 token 的生成速度。位置编码的泛化能力约束了模型理解超长序列的能力。训练成本和数据可用性则从经济角度画了一条底线。最后,即使所有硬约束都被克服了,模型对长上下文信息的有效利用率本身就不完美。
这就是为什么尽管上下文窗口已经从最初的几千 token 增长到了如今的百万级别,这个话题依然热门。研究者们正在从各个角度进攻这个问题——FlashAttention 优化了注意力计算的内存访问模式,Multi-head Latent Attention 用低秩投影压缩 KV 缓存,稀疏注意力让模型不用看完所有 token,状态空间模型(如 Mamba)干脆用线性复杂度的架构来替代传统的 Transformer 注意力。
但到目前为止,还没有哪种方案能在所有维度上同时做到完美。每一种优化都有自己的取舍——压缩 KV 缓存可能损失精度,稀疏注意力可能遗漏关键信息,新架构可能在短上下文任务上表现不如传统 Transformer。
所以下次当你看到某个模型宣传”支持百万 token 上下文”的时候,你可以带着更清醒的视角去理解这个数字:它代表的是一个理论上限,背后是无数工程师在算力、内存、精度和成本之间反复权衡的结果。而在这个上限之内,模型能不能真正记住并用好每一个 token,又是另一个故事了。
发表回复