你有没有注意到,当你向 ChatGPT 或 Claude 等大模型提交一个很长的提示词时,模型几乎是”咔”一下就开始回复了——不管你的输入有多长,等待时间似乎差别不大。但生成回复的过程就不一样了,那些文字是一个字一个字蹦出来的,长回复明显比短回复要等更久。
这背后藏着 LLM 推理中一个非常本质的区别:输入是并行处理的,输出是串行生成的。
理解了这一点,你就理解了当今 LLM 系统中最核心的性能瓶颈之一。
两个阶段:Prefill 和 Decode
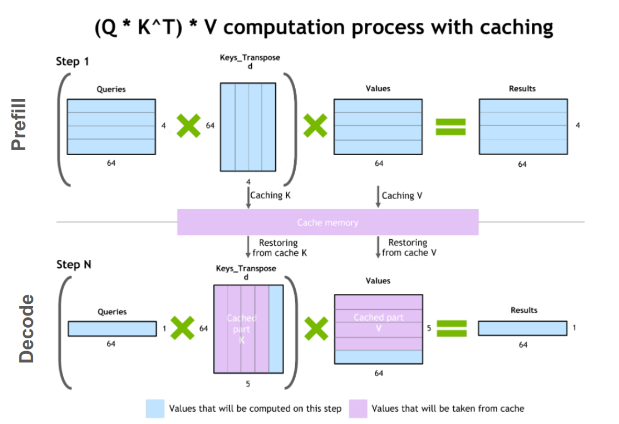
LLM 的推理过程分成两个截然不同的阶段。
第一个阶段叫 Prefill(预填充),也就是模型消化你输入的全部内容的过程。当你把一段提示词丢给模型时,模型需要把所有 token 都”看一遍”,计算出每个 token 的 key 和 value 向量,存进一个叫 KV Cache 的结构里。关键在于——因为所有输入 token 在一开始就已经全部已知了,模型可以把它们一口气全部并行处理。这就是一个大规模的矩阵乘矩阵运算,GPU 上几千个计算核心可以同时火力全开。
第二个阶段叫 Decode(解码),也就是模型一个 token 一个 token 地吐出回复的过程。生成第一个输出 token 后,模型要把它作为输入喂回去,才能生成第二个 token,第二个生成后再喂回去生成第三个……如此循环往复,直到遇到终止符。每一步都依赖于前一步的结果,天然就是串行的,没法并行。
打个比方:Prefill 就像是你把一整本书同时摊开在桌上,让一百个人同时各读一页;Decode 就像是你只有一支笔,得一个字一个字地写回信——你没法在不知道上一个字写了什么的情况下写出下一个字。
为什么一个快一个慢?计算密集 vs 内存密集
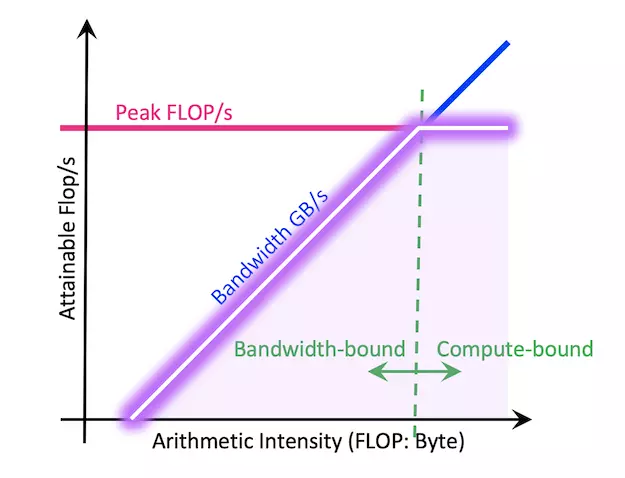
这两个阶段不只是并行和串行的区别,它们在硬件层面的瓶颈也完全不同。
Prefill 阶段是计算密集型(compute-bound)的。所有输入 token 的注意力计算一起进行,形成大矩阵运算,GPU 的 Tensor Core 被充分利用。瓶颈在于 GPU 的算力——能算多快就多快。一个足够长的提示词,单个请求就能把 GPU 的计算能力榨干。
Decode 阶段则是内存密集型(memory-bound)的。每一步只处理一个新 token,对应的计算量很小——本质上是一个矩阵乘向量的操作,GPU 的绝大部分算力闲着没事干。真正的瓶颈变成了数据搬运:把模型权重、KV Cache 从 GPU 的显存(HBM)搬到计算单元的速度。芯片算得飞快,但数据喂不过来。
用数字来感受一下。以 NVIDIA H100 为例,它的半精度算力大约是 990 TFLOPS,显存带宽大约 3.35 TB/s。两者的比值接近 300:1——意味着 GPU 每从显存搬运 1 字节数据的时间里,可以完成大约 300 次浮点运算。Decode 阶段每个 token 的运算强度远低于这个比值,所以绝大多数时间 GPU 都在等数据。那些价值数万美元的计算核心就这样空转着——这是一种巨大的浪费。
自回归的”原罪”
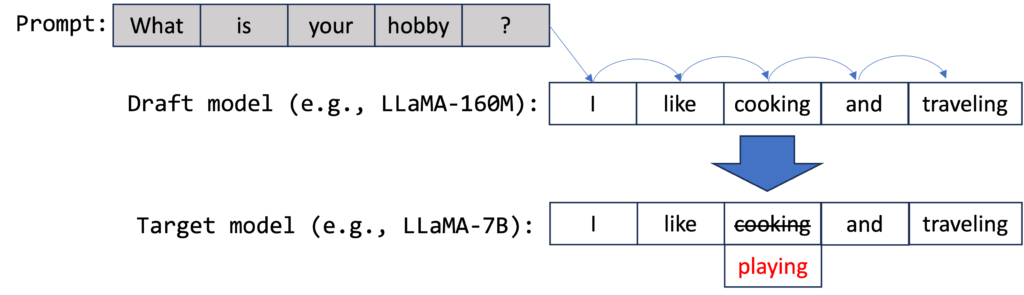
为什么输出必须是串行的?这要追溯到 Transformer 的生成方式。
当今几乎所有主流 LLM——GPT 系列、Claude、Llama——都采用自回归(autoregressive)的方式生成文本。简单说就是:模型在每一步预测”下一个最可能的 token”,然后把这个 token 加到已有序列里,再预测下下一个。每个 token 的生成都以前面所有 token 为条件。
这和训练时的情况形成了有趣的对比。训练时,目标序列是已知的,模型可以用因果掩码(causal mask)一次性并行处理整个序列,算出每个位置的损失。但推理时不行——你不知道下一个 token 是什么,只有生成出来了才知道。这就是自回归模型的”原罪”:训练时天然并行,推理时天然串行。
有人可能会问:那能不能像扩散模型(diffusion model)那样,一次性并行生成所有 token?理论上这是一个研究方向,但目前的自回归范式之所以占据统治地位,恰恰是因为它在训练效率和生成质量上的综合表现最好。每个 token 都条件于前文,这种逐步细化的方式天然适合语言这种高度序列化的数据。
业界怎么对付这个问题
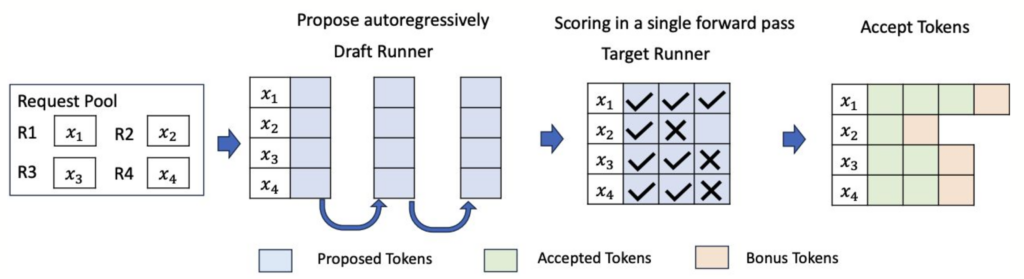
既然 Decode 阶段又慢又浪费算力,工程师们自然想了很多办法来优化。
批处理(Batching) 是最直接的思路。既然单个请求在 Decode 阶段只用到很少的算力,那就把多个请求打包在一起处理。模型权重只需要从显存加载一次,就能同时服务多个用户。这大幅提高了吞吐量,虽然对单个用户的延迟帮助有限,但对于服务提供商来说,意味着同样的 GPU 能服务更多人。
KV Cache 本身就是一种优化。如果不缓存之前计算过的 key 和 value 向量,每生成一个新 token 都要重新处理整个序列,那就更慢了。KV Cache 用空间换时间,避免了大量重复计算。当然,它也带来了显存压力——对于长上下文的对话,KV Cache 的大小可能远超模型本身的权重。
Prefill-Decode 解耦 是一种更激进的架构优化。既然两个阶段对硬件的需求完全不同,何不把它们分开部署到不同的机器上?Prefill 密集计算,给它配高算力的 GPU;Decode 密集搬运数据,给它配高带宽的 GPU。两者互不干扰,各自拉满。Perplexity、vLLM、SGLang 等推理框架都在探索这种方向。
但最有意思的可能是推测解码(Speculative Decoding)。
推测解码:用”猜测”换取并行
推测解码的核心思想源自 CPU 设计中的一个经典技术——分支预测(branch prediction)。
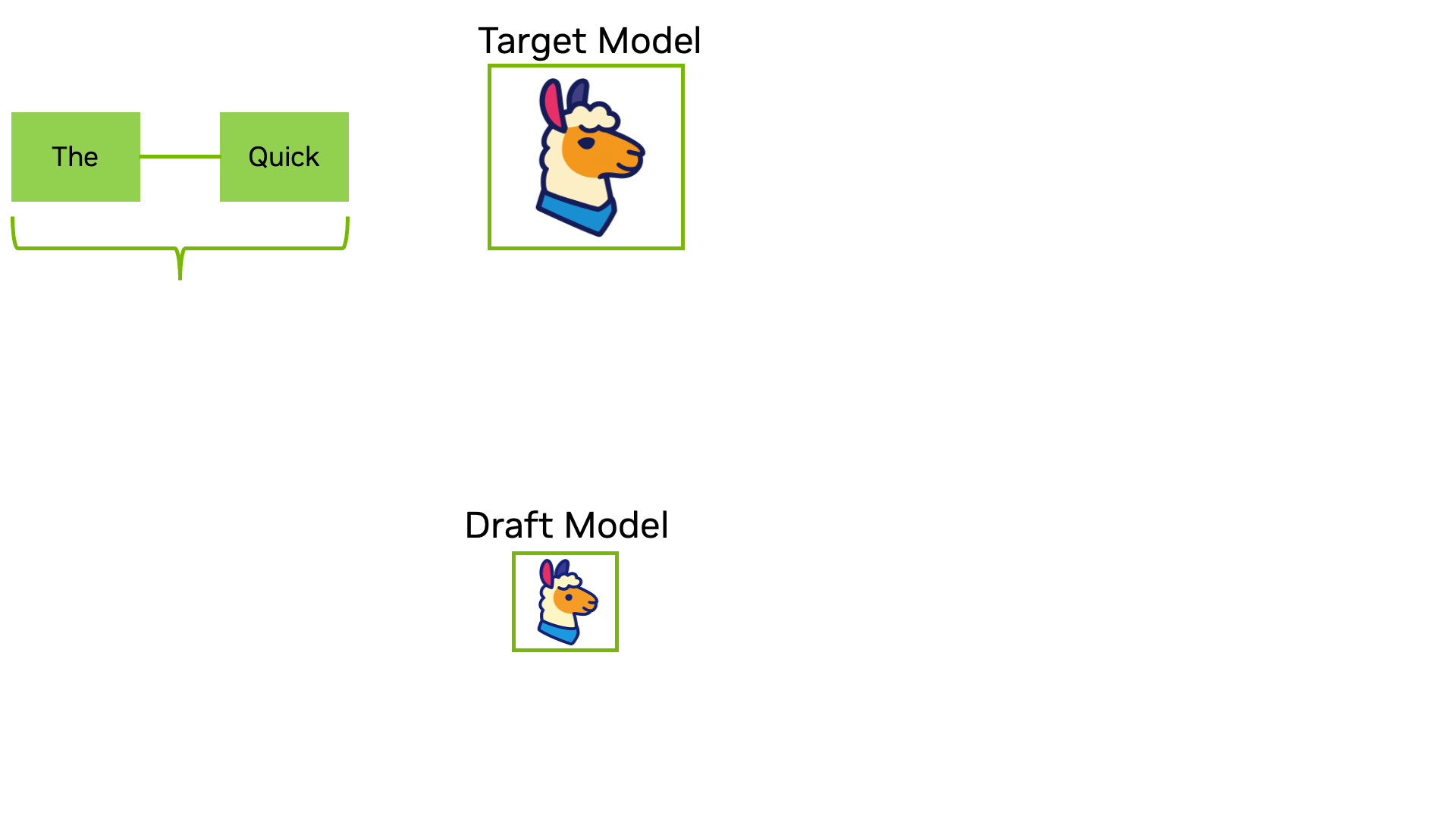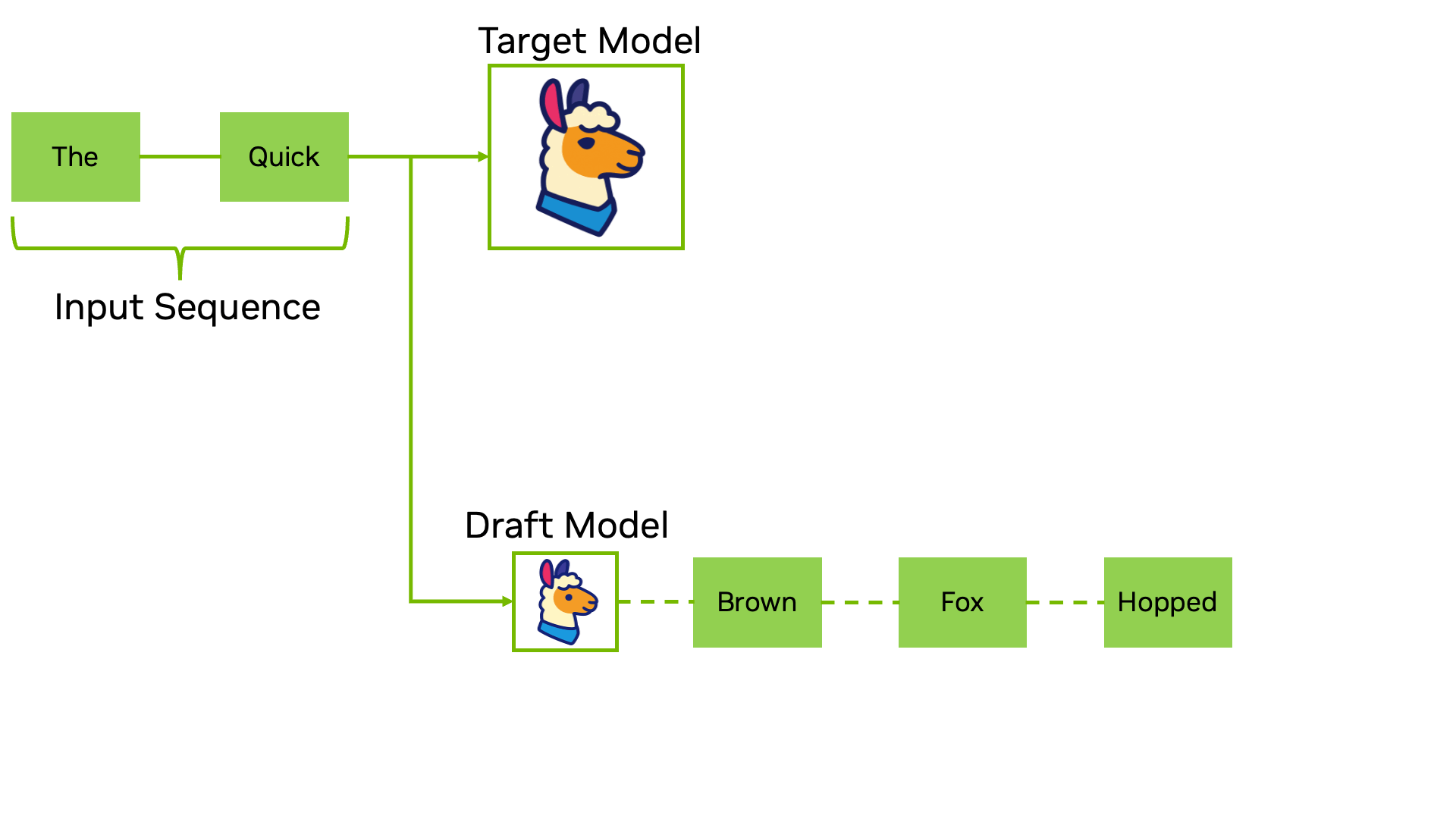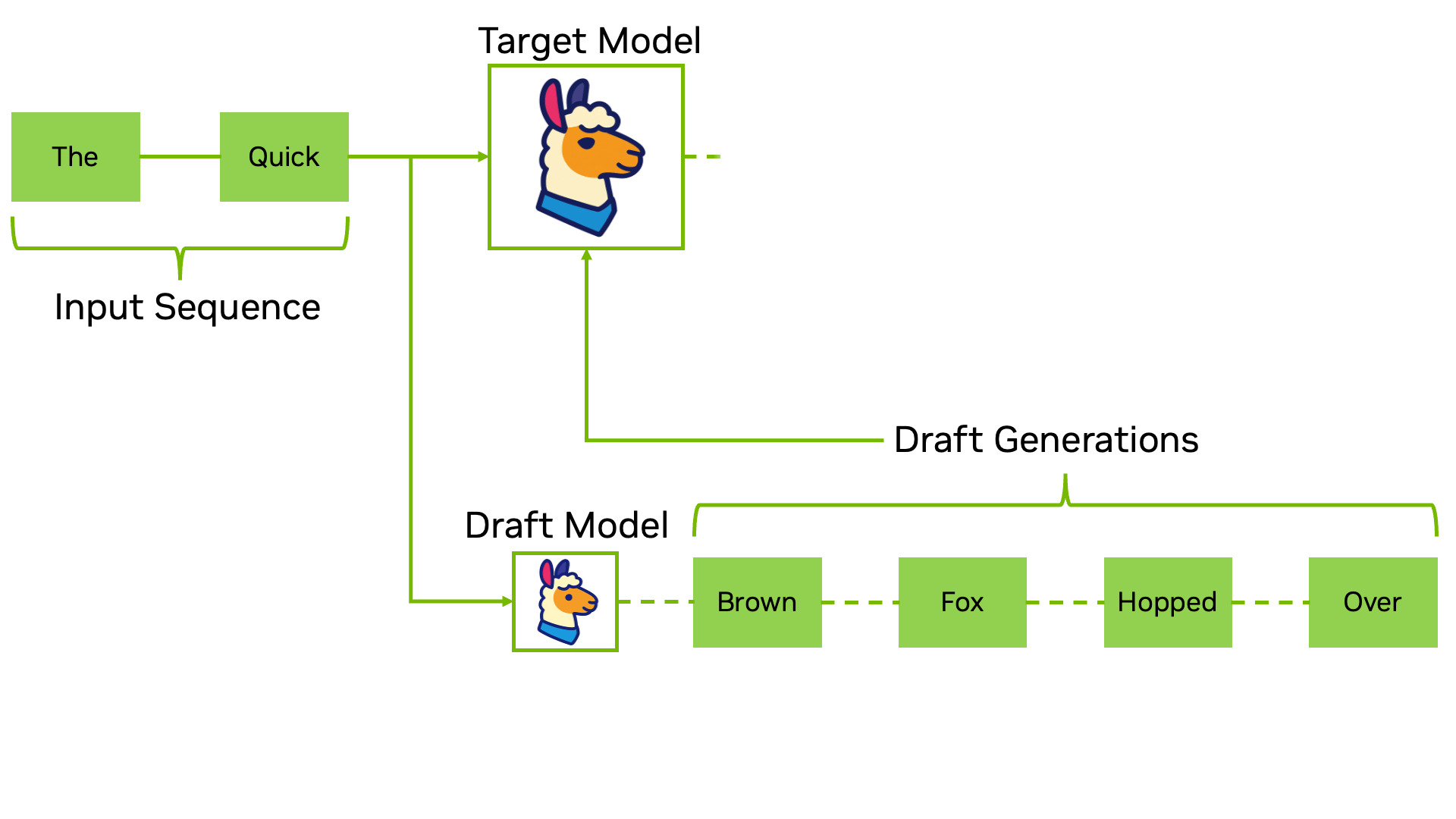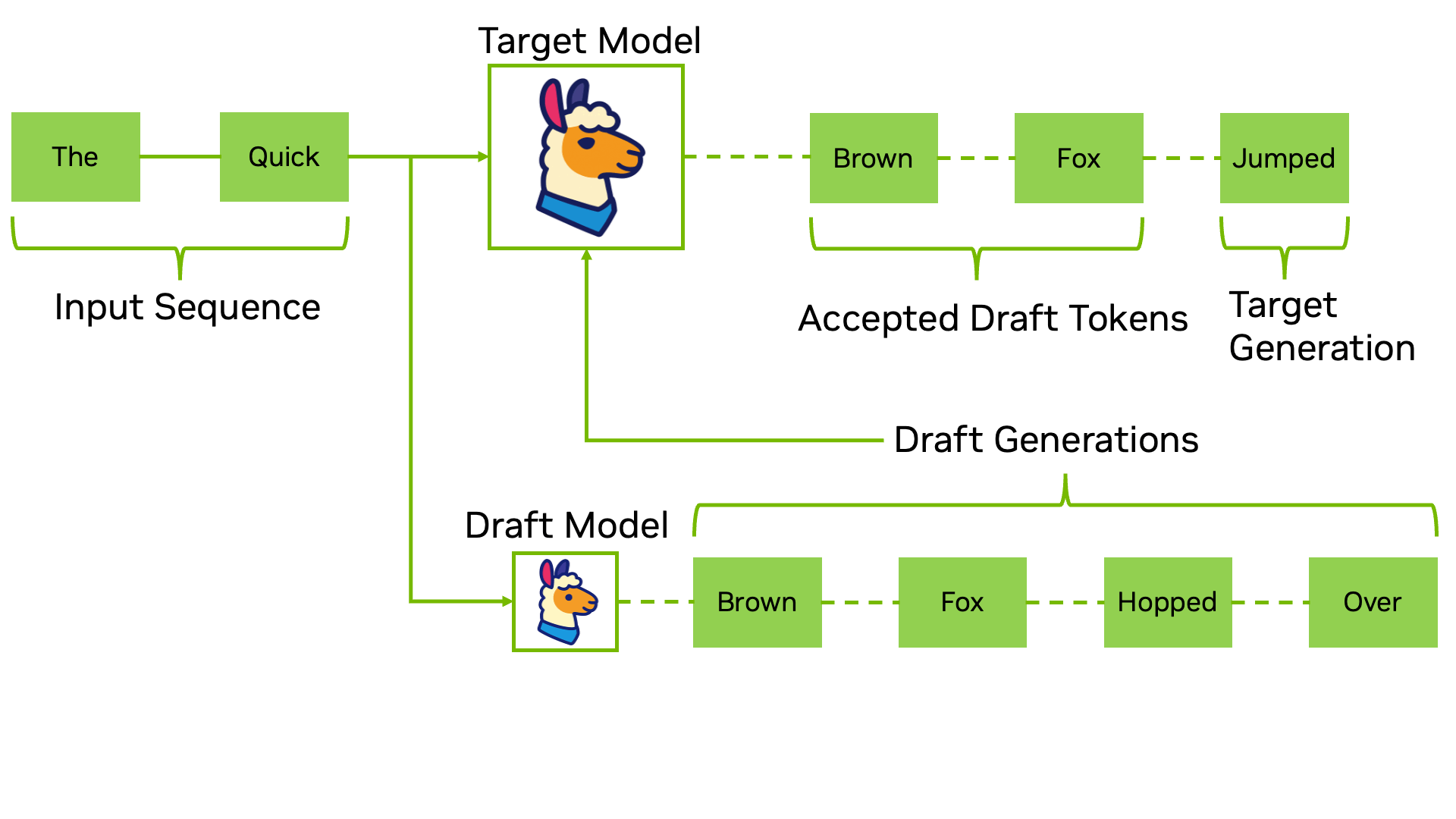
它的工作方式是这样的:找一个又小又快的”草稿模型”(draft model),让它先快速地一口气猜出好几个 token。然后,把这些猜测的 token 一起交给真正的大模型去验证。验证的过程本质上类似于 Prefill——大模型可以并行处理这一串 token,检查自己是否也会生成同样的结果。如果猜对了,就等于一次前向传播生成了多个 token;如果猜错了,就从错误的地方开始修正。
最妙的是,通过精心设计的拒绝采样机制,这个过程可以保证输出的概率分布和原始模型完全一致——你得到的是一模一样的回答,只是更快。Google 在 2022 年首次提出了这个方法,实测在翻译和摘要任务上获得了 2 到 3 倍的加速。如今,推测解码已经被广泛应用在 Google 搜索的 AI 概述等大规模产品中。
后续的研究还在不断推进这个方向。EAGLE 系列方法直接在大模型内部加一个轻量级的预测头,省去了独立的草稿模型。还有研究者尝试用扩散模型来生成草稿序列,让”猜测”这一步本身也能并行化,在某些场景下实现了高达 8 倍以上的加速。
更深的视角:这不只是工程问题
如果你退一步看,”输入快、输出慢”这件事其实反映了当前语言模型的一个根本性质:理解可以并行,但生成必须串行。
这和人类的认知方式有某种有趣的呼应。我们可以一眼扫过一整页文字,大脑并行处理大量视觉和语义信息;但当我们要组织语言说出一句话、写出一段文字时,却必须一个词一个词地线性展开。思想的形成可能是并行的、弥散的,但表达的过程不可避免地是串行的。
当然,这个类比也提示了一种可能的未来方向。有研究者指出,并非所有的思考都需要线性化——人类常常先有一个模糊的”整体想法”,然后才逐步细化为语言。如果未来的模型架构能在某种程度上打破自回归的串行约束——比如先并行地规划一个回复的结构,然后再逐步填充细节——那或许能在保持质量的同时大幅提升速度。
但至少在今天,Transformer 架构下的自回归生成仍然是那个不可绕过的瓶颈。当你看着屏幕上的文字一个一个蹦出来的时候,你看到的不只是一个交互动画——你看到的是 GPU 正在拼命地、一步一步地从概率分布中采样出每一个 token。
它在努力思考。而思考,需要时间。
发表回复