如果你用过 OpenAI 的 Whisper 来做语音转文字,你大概率见过一些莫名其妙的输出。你明明只是给它喂了一段普通的录音,它却在沉默的片段里凭空冒出这么些东西:
“本字幕由 Amara.org 社区提供”
“Thanks for watching!”
“Subscribe to my channel!”
“Subtitles by the Amara.org community”
“Sous-titres réalisés par la communauté d’Amara.org”
“Copyright WDR 2021”
你没听错——这些文字在原始音频里压根不存在。没人说过”感谢观看”,更没人让你去订阅什么频道。但 Whisper 言之凿凿地把这些东西写进了转录结果里,就好像它亲耳听到了一样。
这到底是怎么回事?
一切要从 68 万小时说起
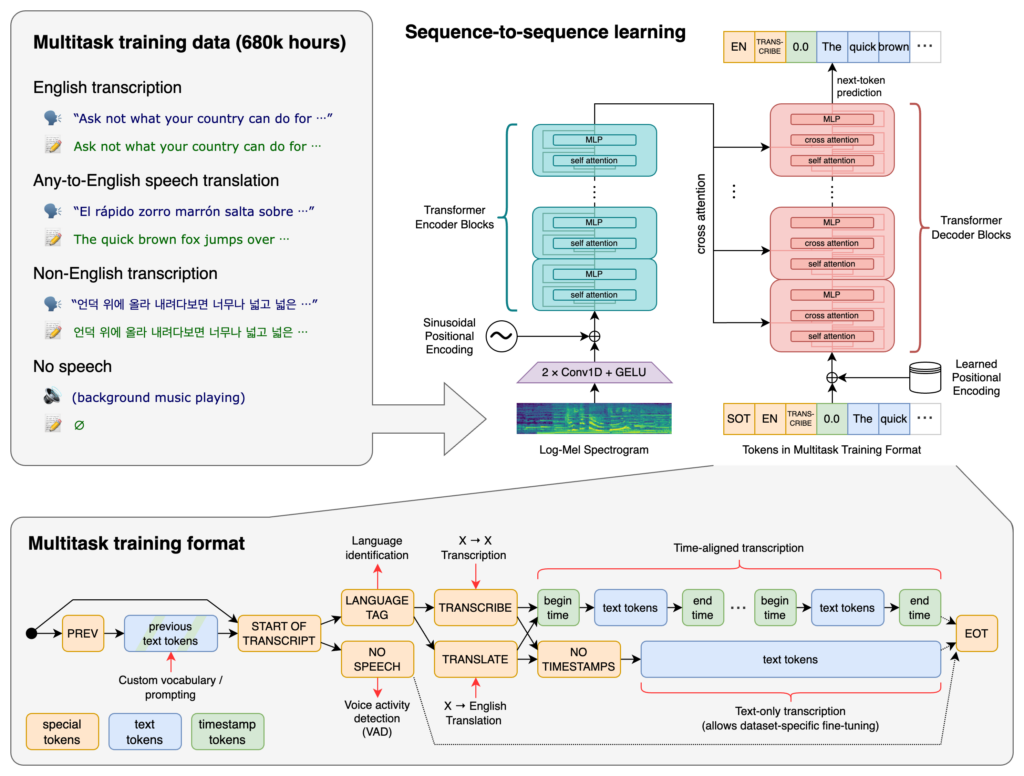
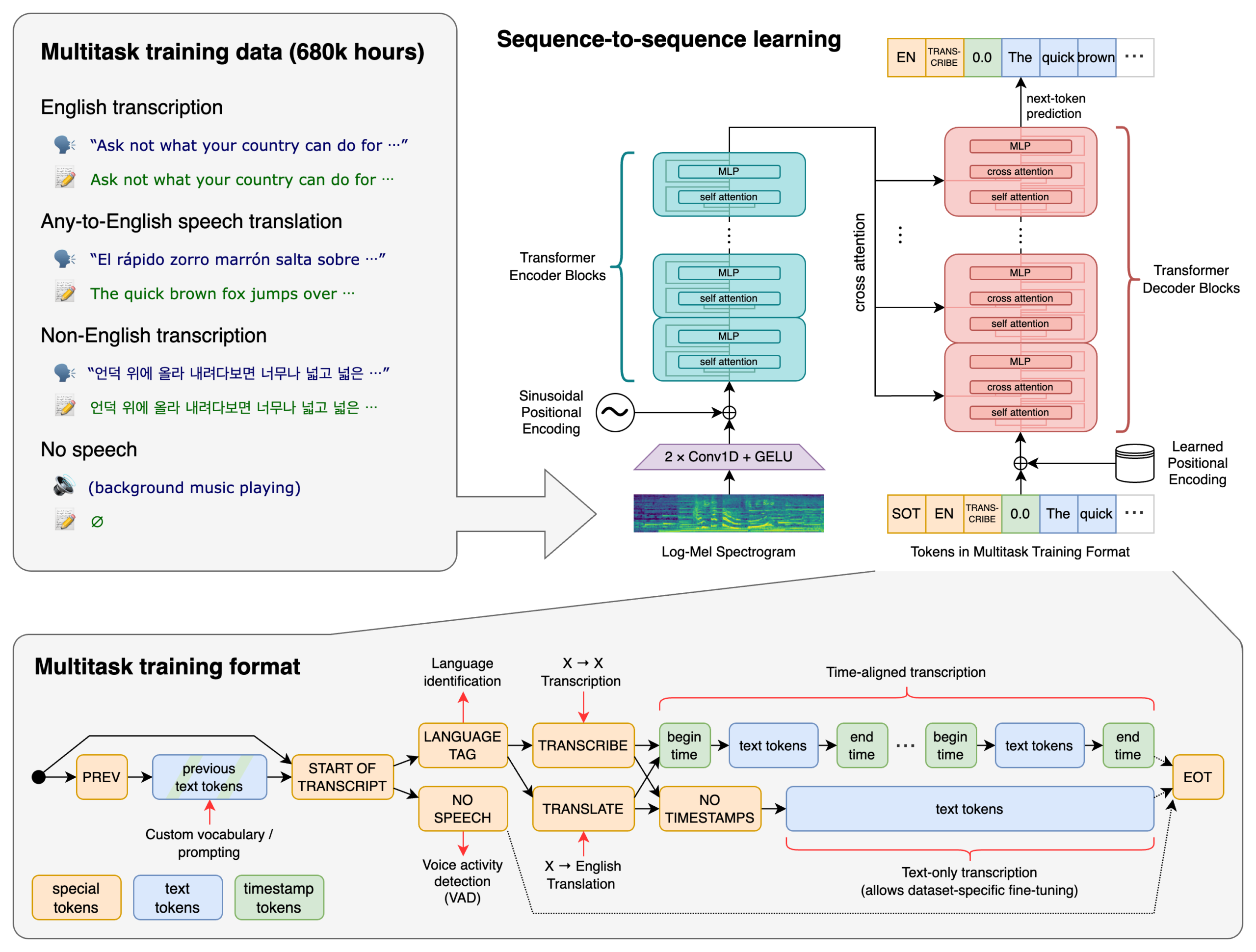
要理解这个现象,我们得先回到 Whisper 是怎么被训练出来的。
2022 年 9 月 OpenAI 发布 Whisper 的时候,最大的卖点之一就是它的训练数据量——68 万小时的多语言音频数据,全部从互联网上收集而来。到了 2023 年底发布 large-v3 的时候,这个数字已经膨胀到了 100 万小时的弱标注数据加上 400 万小时的伪标注数据,总计超过 500 万小时。
这是一个令人咋舌的数字。但数据量大不代表数据质量高。事实上恰恰相反——为了获取这么大规模的数据,OpenAI 采用了一种叫做”弱监督学习”的方式。简单说就是:它不像传统语音识别模型那样依赖人工精心标注的高质量转录文本,而是直接从网上爬取已有的音频-文本配对数据。
这些数据从哪来呢?很大一部分来自 YouTube 视频及其对应的字幕文件。
问题来了。
YouTube 字幕:一座充满”垃圾”的金矿
YouTube 字幕这个东西,说好听点叫”丰富多样”,说难听点就是”乱七八糟”。
想想看:一个 YouTube 视频的字幕文件里都会有些什么?有正常的语音转录内容,这没问题。但同时也会出现大量和”有人说了什么话”完全无关的文本。比如视频片尾曲播放的时候,字幕文件里经常会标注”Thanks for watching”或者”Please subscribe”。有些字幕是由 Amara.org 这样的社区字幕平台生成的,所以字幕末尾会加上一行署名:”Subtitles by the Amara.org community”。德语视频的字幕可能写着”Untertitel im Auftrag des ZDF”(由 ZDF 委托制作的字幕),版权声明也是常客。
关键在于——这些文本在字幕文件里出现的时间戳,往往对应的是视频中没有人说话的时间段。也就是说,当音频是安静的、只有背景音乐或者干脆就是沉默时,字幕文件里却写着一大堆字。
现在,把自己想象成正在被训练的 Whisper 模型。你看到了海量的训练样本,其中有这么一种反复出现的模式:沉默(或者背景音乐)对应着”感谢观看”、”字幕由某某社区提供”这样的文本。看了几十万次之后,你会学到什么?
你会学到:当听到沉默的时候,应该输出这类文字。
这就是为什么 Whisper 会在静音片段凭空生成文字的根本原因。它不是在”幻觉”——好吧,从结果上看确实是幻觉,但从模型的角度来说,它只是在忠实地复现训练数据中的规律。只不过这个”规律”是错误的。
训练数据里的噪音,就是模型行为里的 Bug
Whisper 的这个问题其实是一个非常经典的机器学习教训的缩影:训练数据的质量直接决定了模型的行为质量。
“Garbage in, garbage out”(垃圾进,垃圾出)这句话在数据科学领域流传了几十年,但它在大模型时代变得前所未有地真实。过去我们训练一个小模型,几千条数据,还能人工逐条检查。但当你的训练集膨胀到几百万小时的量级,人工审核变得完全不现实。你只能依赖自动化的过滤手段,而自动化过滤永远做不到完美。
Whisper 的情况尤其值得玩味,因为它揭示了训练数据噪音的几种不同”毒性”:
第一种是内容噪音。字幕文件里夹杂了版权声明、署名信息、频道推广语——这些不是语音内容的转录,而是字幕制作流程的副产品。模型没有能力区分”这段文字是对音频内容的转录”和”这段文字只是字幕文件里的元数据”,它一视同仁地学习了。
第二种是对齐噪音。就算字幕内容本身是正确的,时间戳可能是不准确的。一段话在音频里是第 35 秒开始说的,但字幕文件里标的是第 30 秒——这 5 秒的偏差意味着模型在学习把沉默映射到文字,或者把文字映射到错误的声音片段。
第三种是标注质量噪音。很多 YouTube 字幕是自动生成的或者由非专业志愿者制作的,拼写错误、漏听、误听都是家常便饭。这些错误会被模型原样学走。
2024 年发表的一篇叫《Careless Whisper》的学术论文对这个问题做了系统性的研究。研究者发现 Whisper 大约有 1% 的转录会出现幻觉——听起来比例不大,但考虑到 Whisper 被用于医疗记录转录、法庭证词处理、新闻采编等场景,1% 的幻觉率意味着每转录 100 段音频就可能有一段出现凭空捏造的内容。
更有意思的是,这篇论文测试了 Google、Amazon、Microsoft、AssemblyAI 和 RevAI 等其他语音转文字服务,在同样的 187 个测试音频片段上,这些竞品的幻觉数量是——零。这说明幻觉不是语音识别这个任务本身固有的缺陷,而是 Whisper 特定的训练数据和训练方式导致的问题。
模型学到的不是你想教的
如果我们把视角再拉远一点,Whisper 的案例其实在讲一个更深层的道理:模型学到的东西,往往不是你以为你在教它的东西。
你以为你在教它”听到人说话就把内容写下来”。但模型实际学到的是一个更宽泛的映射关系——”对于任意音频输入,找到在训练数据中与之关联概率最高的文本输出”。当输入是正常语音时,这两个目标恰好一致。但当输入是沉默、背景噪音或者音乐时,二者就分道扬镳了。
2025 年的一篇论文《Calm-Whisper》进一步揭示了一个有趣的细节:在 Whisper-large-v3 的解码器中,20 个自注意力头里只有 3 个贡献了超过 75% 的幻觉。研究者把这三个头叫做”crazy heads”(疯狂头),通过只对这三个头进行微调,就实现了超过 80% 的幻觉减少率,同时对正常语音的识别精度几乎没有影响。
这说明什么?说明幻觉行为在模型内部是高度局部化的。训练数据中的噪音模式并不是均匀地”污染”了整个模型,而是被特定的神经网络组件”记住”了。这就像人脑的某些区域负责特定的功能一样——模型的某些”头”专门学会了”沉默时该编什么故事”。
规模与质量的永恒拉扯
这里面有一个根本性的张力:数据规模和数据质量之间的权衡。
传统的语音识别研究用的是精心标注的小型数据集——几千甚至几万小时,每一段都经过人工审核。这样做的好处是数据干净,坏处是规模不够,模型泛化能力受限。
Whisper 走了反方向的极端:用 68 万小时的”脏”数据换来了前所未有的泛化能力。它能处理各种口音、各种背景噪音、各种录音质量的音频,这在传统模型上是不可想象的。但代价就是那些幽灵般的”感谢观看”。
这其实是整个大模型时代的缩影。GPT 系列、Claude、Gemini 等大语言模型都面临同样的问题:用互联网规模的数据训练出来的模型能力惊人,但互联网上的数据本身就是一个大杂烩。偏见、错误信息、过时内容、各种格式的噪音——模型全都照单全收了。
有研究指出,用 AI 生成的内容来训练下一代 AI 模型会导致”模型坍塌”——就像反复复印一张照片,每一代都会比上一代更模糊,最终变成一团无法辨认的色块。牛津大学的研究者把这比作”给照片拍照再拍照”,噪音会在每一轮迭代中被放大。
打补丁还是治根本?
面对训练数据噪音的问题,业界目前的应对策略大致分几条路线。
最直接的是后处理过滤。维护一个”已知幻觉短语”列表——”Thanks for watching”、”Subscribe to my channel”、”Subtitles by…”——然后在输出时过滤掉。简单粗暴但有效。缺点是只能处理已知模式,新出现的幻觉会漏掉。
第二种是前处理优化。在把音频喂给 Whisper 之前,先用语音活动检测(VAD)工具把静音和无人说话的段落删掉。既然幻觉主要发生在静音时段,那就不给它制造幻觉的机会。
第三种是模型层面的修复。比如前面提到的 Calm-Whisper 方法,定位到负责幻觉的特定注意力头,然后用干净的非语音数据对这几个头进行微调。这是一种相当精准的手术式修复。
但最根本的解决方案,说到底还是要在数据层面下功夫。清洗训练数据、剔除字幕文件中的元数据、修正时间戳对齐、过滤掉低质量标注——这些活儿枯燥乏味,远没有设计新模型架构那么性感,但它们可能是对最终产品质量影响最大的工作。
有开发者发现,只要把推理模型从 int8 量化切换到 float16 精度,再用一些噪音和静音音频做微调,就能大幅减少幻觉。这告诉我们:有时候问题的解法不在模型有多大多先进,而在对细节的关注。
写在最后
Whisper 的”感谢观看”现象是一个极好的教学案例。它用一种几乎滑稽的方式告诉我们:机器学习模型并不理解它在做什么,它只是在数据中找模式。当数据里有垃圾模式时,模型会忠实地复现这些垃圾。
下次你用语音转文字工具的时候,如果它突然跟你说”别忘了点赞关注”,不用害怕——它不是有了自我意识在搞推广。它只是在重复它见过太多次的东西,就像一个在 YouTube 视频海洋里泡了太久的孩子,张嘴闭嘴都是那些片尾套话。
某种意义上,Whisper 的幻觉是互联网内容生态的一面镜子。当”感谢观看请订阅”成为了互联网视频的标配,当每一个 YouTube 视频都以同样的套路结尾,这些重复的模式就深深地刻进了从这些数据中诞生的 AI 的”骨子里”。
AI 学到了什么,取决于我们喂给它什么。这个道理简单得近乎庸俗,但 Whisper 用最直观的方式证明了它仍然是最重要的一课。
发表回复