如果你在 2024 或 2025 年部署过大语言模型,你大概率用过 vLLM,或者至少听过它的名字。在 LLM 推理引擎这个赛道里,vLLM 几乎是绕不过去的存在。它不是最早出现的,也不敢说永远最快,但它确实是第一个让大家意识到”原来推理效率还能提升这么多”的项目。

这篇文章想带你搞清楚它到底解决了什么问题、怎么解决的、以及它的设计思路为什么值得深入理解。
故事要从 KV Cache 说起
要理解 vLLM,你得先理解大语言模型推理时最大的瓶颈在哪里。
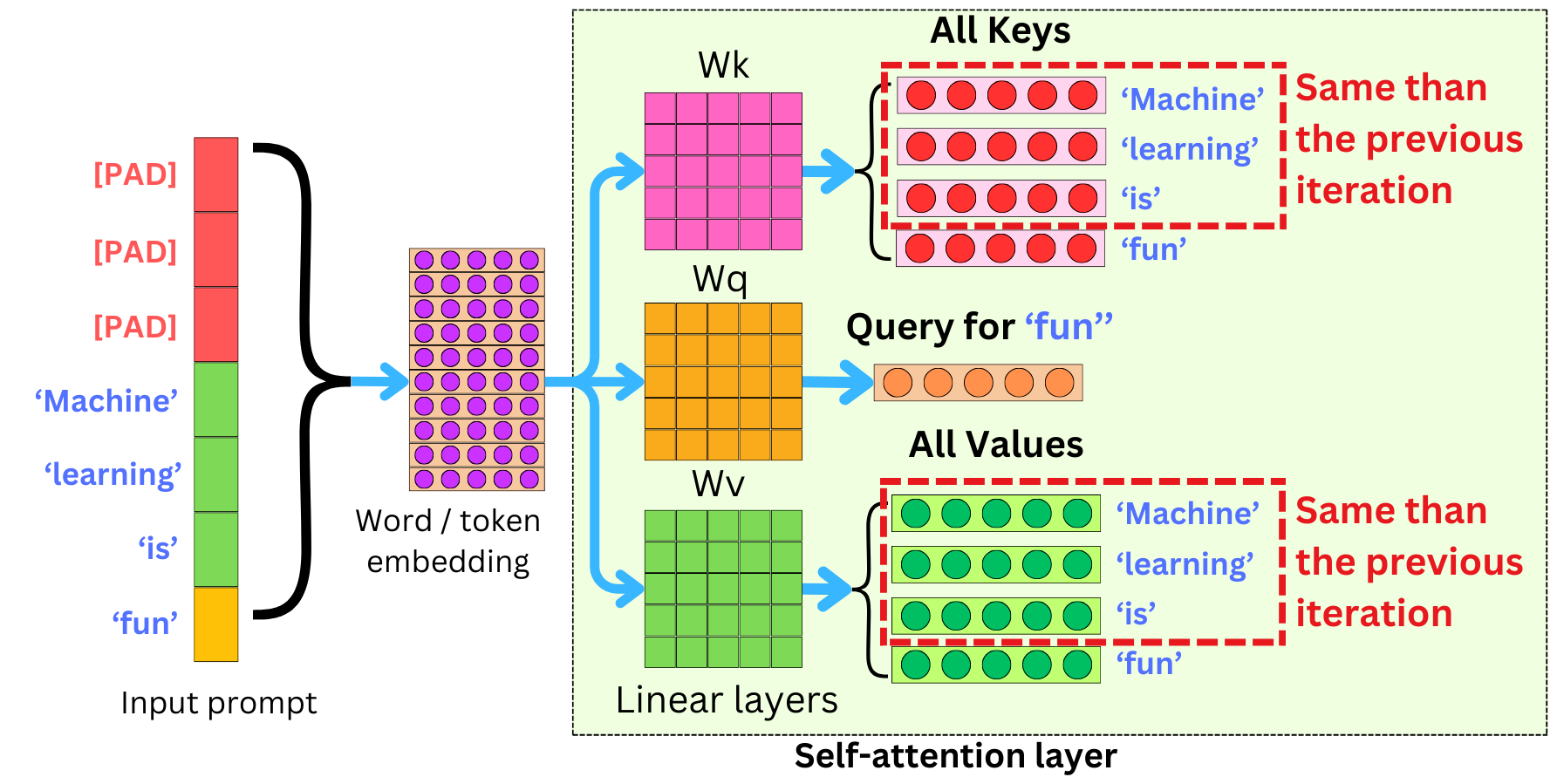
大语言模型生成文本是自回归的——每次只吐一个 token,然后拿着已经生成的所有 token 再去预测下一个。这个过程中,模型需要反复计算注意力(Attention),而注意力机制的核心是 Query、Key、Value 三组向量的交互。为了避免每一步都从头计算所有历史 token 的 Key 和 Value,业界早就采用了 KV Cache 的做法:把之前算过的 Key 和 Value 缓存下来,后续生成新 token 时直接复用。
问题在于,这个 KV Cache 是个内存大户。以 LLaMA-13B 为例,单个请求的 KV Cache 就可能占到 1.7GB。更麻烦的是,它的大小完全取决于序列长度,而序列长度又是动态变化的、不可预测的。你不知道用户会问一句话还是写一篇论文。
传统的做法是给每个请求预分配一块连续的 GPU 内存,按最大序列长度来留空间。这就好比你去餐厅吃饭,老板非要给你预留一张十人桌,哪怕你只有两个人。结果就是大量的内存被白白浪费了。
vLLM 的论文里有一个惊人的数字:在传统推理系统中,KV Cache 分配出去的内存只有 20%–38% 真正被用上了。剩下的全浪费在三种场景里——内部碎片(预留了但没用完)、外部碎片(分配之间的间隙)、以及为未来可能的增长预留的空间。
这就是 vLLM 想要解决的核心问题。
PagedAttention:操作系统课本里翻出来的灵感
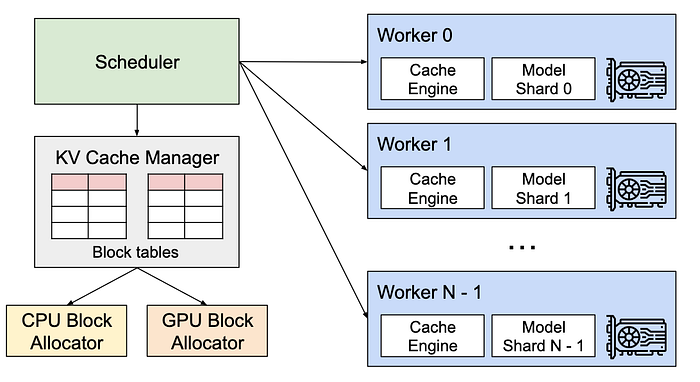
vLLM 的核心创新叫做 PagedAttention,名字本身就透露了灵感来源——操作系统中的虚拟内存和分页机制。
学过操作系统的人都知道,早期计算机要求程序占用连续的物理内存,导致严重的内存碎片问题。后来操作系统引入了虚拟内存:把物理内存切成固定大小的”页”(Page),程序看到的是连续的虚拟地址空间,但实际上这些页可以散落在物理内存的任何位置。程序不需要关心物理布局,操作系统通过页表(Page Table)来完成虚拟地址到物理地址的映射。
PagedAttention 把同样的思路搬到了 KV Cache 的管理上。它不再要求一个请求的 KV Cache 存储在连续内存中,而是把它切成固定大小的”KV Block”——默认是 16 个 token 一个 block,在 13B 模型上大约 12.8KB。这些 block 可以分散在 GPU 内存的任何位置,通过一个 block table(类似页表)来维护逻辑到物理的映射关系。
在注意力计算的时候,PagedAttention 内核通过 block table 找到每个 block 的实际位置,逐块读取 Key 和 Value 进行计算。虽然这些 block 在物理上不连续,但计算结果和传统的连续存储完全一致。
这种设计带来几个直接好处。首先,外部碎片彻底消失了——不再需要连续的大块内存,block 可以见缝插针。其次,内部碎片被压到了最小——每个请求最多只在最后一个 block 里浪费 15 个 token 的空间(block_size – 1)。最后,block 可以按需分配——处理 N 个 token 只需要 ceil(N / block_size) 个 block,不必提前为最大长度预留。
效果是什么呢?vLLM 把 KV Cache 的内存浪费从 60%–80% 降到了不到 4%。这意味着同样的 GPU 内存里可以塞进更多的请求,batch size 上去了,吞吐量自然就暴涨。实测下来,相比 HuggingFace Transformers 最高有 24 倍的吞吐提升,相比 HuggingFace TGI 也有 3.5 倍。
当然,天下没有免费的午餐。PagedAttention 引入了一定的 per-kernel 开销——大约 20%–26%——因为非连续的内存访问模式对 GPU 不那么友好。但在系统层面,内存利用率的大幅提升远远盖过了这点额外开销,最终的端到端吞吐量反而提升了 2–4 倍。这就是经典的”用微观的小代价换宏观的大收益”。
还不止是分页:Copy-on-Write 和内存共享
PagedAttention 的好处不止于减少浪费,它还打开了内存共享的大门。
考虑一个常见的场景:并行采样(Parallel Sampling),即同一个 prompt 生成多个不同的回复。在传统系统里,每个回复都需要独立存储完整的 KV Cache,包括 prompt 部分——即使它们的 prompt 完全一样。这是巨大的冗余。
在 vLLM 里,多个输出序列的 prompt 部分可以共享同一组物理 block。系统通过引用计数来跟踪每个 block 被多少个序列使用。当某个序列需要修改一个共享 block(比如在最后一个 block 里追加不同的 token)时,vLLM 采用 Copy-on-Write 机制:先复制一份新 block,再在新 block 上修改,原 block 保持不变。
这和操作系统里 fork 进程后的 Copy-on-Write 完全是同一个模式。也正是这种设计,让 vLLM 在 Beam Search、并行采样等多输出场景下的内存效率远超同类系统。
Continuous Batching:让 GPU 永远不闲着
光有高效的内存管理还不够,调度策略同样关键。
传统的推理系统使用”静态批处理”——收集到一批请求后统一处理,等这一批全部完成了再处理下一批。问题很明显:如果一批里有一个请求特别长,其他已经完成的请求只能干等着。GPU 的利用率就这样被拖下来了。
vLLM 从一开始就采用了 Continuous Batching(连续批处理),或者说 iteration-level scheduling。它不再以”请求”为粒度,而是以”迭代步骤”为粒度做调度。每一步 forward pass 之前,调度器都重新决定哪些请求参与这一步计算。某个请求生成完毕?立刻移出,腾出空间给等待队列里的新请求。不用等整个 batch 跑完,GPU 始终保持忙碌。
这个想法并非 vLLM 首创——Orca 论文最早描述了这种机制——但 vLLM 将它与 PagedAttention 深度整合,两者配合使得系统在高并发场景下表现尤为出色。
进阶特性:让推理再快一点
vLLM 走到今天,早已不只是”一个 PagedAttention”那么简单。围绕核心架构,它叠加了一系列进阶优化。
Chunked Prefill 是其中之一。当一个很长的 prompt 进来时,”预填充”(Prefill)阶段需要处理全部 prompt token,这可能一次性占掉大量计算资源,挤压正在进行解码的其他请求。Chunked Prefill 把长 prompt 拆成小块,和解码请求交错处理,避免 prefill 风暴导致其他请求的延迟飙升。
Prefix Caching 则是另一个巧妙的优化。很多场景下,不同请求会共享相同的前缀——比如同一个系统提示(System Prompt),或者多轮对话中重复出现的历史消息。vLLM 通过基于哈希的自动前缀缓存,识别并复用已经计算过的前缀 KV Cache,避免重复计算。在多轮对话场景下,这意味着只有最新一轮的用户消息需要做 prefill,之前的历史全部命中缓存。实测显示,一个约 10,000 token 前缀的请求,第二次发送时 TTFT(首 token 延迟)可以从 4.3 秒降到 0.6 秒。
Speculative Decoding(投机解码)是降低延迟的又一利器。传统自回归生成中,每个 token 都需要一次完整的 forward pass,这在大模型上代价高昂。投机解码的思路是引入一个小的 draft 模型,先快速猜测接下来的 k 个 token,然后用大模型一次性验证。大模型的单次 forward pass 可以并行检查 k 个候选 token,接受正确的、纠正错误的。数学上可以证明,这种方法的输出分布和纯粹从大模型逐 token 采样完全一致——是无损的加速。vLLM 在低 QPS 场景下通过投机解码实现了最高 2.8 倍的加速,不过在高并发场景下效果会打折扣,因为额外的计算开销在系统已经接近算力瓶颈时反而成了负担。
V1 架构:推倒重来的勇气
2025 年 1 月,vLLM 团队发布了 V1 架构的 alpha 版本,这是一次大规模的内部重构。
V1 的核心改变是统一调度器。在 V0 时代,prefill 和 decode 是两个独立的阶段,调度器要么组一个纯 prefill batch,要么组一个纯 decode batch。各种优化功能之间的兼容性也是一团乱麻——chunked prefill 和多步调度不能同时开启,prefix caching 有时候会带来额外的 CPU 开销反而拖慢性能。
V1 统一了一切。调度决策被简化为一个字典:{request_id: num_tokens},指定每一步给每个请求分配多少 token。这个表示足够通用,chunked prefill、prefix caching、speculative decoding 都可以在同一个框架下自然表达。一个 batch 里可以同时包含正在做 prefill 的新请求、正在做 chunked prefill 的长请求、和正在做 decode 的旧请求。不再有”非此即彼”的割裂。
V1 还将 prefix caching 默认开启,并且重新实现为零开销的版本——即使在缓存命中率很低的情况下也不会拖慢性能。FlashAttention 3 的集成也是 V1 的重要拼图,它提供了足够灵活的注意力内核来支持 V1 中混合 batch 的高度动态性。
从 0.8.0 版本开始,V1 成为了默认引擎。用户不再需要手动调参就能获得接近最优的性能,这对于降低上手门槛意义重大。
溯源:从伯克利实验室走出来的项目
vLLM 最早诞生于 UC Berkeley 的 Sky Computing Lab,核心发起人是 Woosuk Kwon,他的导师是大名鼎鼎的 Ion Stoica——就是那位带出了 Spark 和 Ray 的教授。2023 年的 SOSP 论文奠定了 vLLM 的学术基础,同年 6 月项目正式开源。
有趣的是,vLLM 最早的实战部署场景是 LMSYS 的 Chatbot Arena。这个广受欢迎的 LLM 评测平台在 2023 年 4 月就已经开始使用 vLLM 作为后端——比 vLLM 正式开源还早了两个月。随着 Chatbot Arena 流量暴涨到原来的 5 倍,原先基于 HuggingFace Transformers 的后端根本扛不住,换成 vLLM 之后才平稳度过了流量高峰。这算是 vLLM 的第一次实战检验。
到了今天,vLLM 已经从一个学术项目演变为一个社区驱动的工业级项目。UC Berkeley、Red Hat(收购了 Neural Magic)、Anyscale、Roblox 等机构都深度参与了开发。Meta、Mistral AI、Cohere、IBM 等公司在生产环境中使用 vLLM。Stripe 甚至公开表示,迁移到 vLLM 后推理成本降低了 73%,同样的 5000 万日调用量只需要原来三分之一的 GPU。
硬件支持方面,vLLM 也早已不局限于 NVIDIA GPU——AMD GPU、Intel CPU/GPU、TPU、AWS Trainium/Inferentia、华为昇腾等平台都在支持范围内。
竞争者:SGLang 与赛道格局
聊 vLLM 不能不提 SGLang。这两个项目有着深厚的渊源——SGLang 的核心发起人 Lianmin Zheng 同样出自 Berkeley,和 Woosuk Kwon 同在 Ion Stoica 门下。SGLang 比 vLLM 晚了大约半年开源,但发展势头凶猛。
SGLang 的核心差异化在于 RadixAttention——一种自动化的跨请求 KV Cache 复用机制。如果说 vLLM 的 PagedAttention 优化的是单个请求内部的内存管理,RadixAttention 更擅长在多个请求之间发现和利用共享前缀。这在 Agent 场景、多轮推理场景下优势明显。
从性能上看,SGLang 在不少基准测试中表现优于 vLLM,尤其是在复杂的多步调用场景下。它自称在全球超过 40 万块 GPU 上运行,被 xAI、AMD、NVIDIA、Cursor 等机构采用。
但 vLLM 也远没有被甩在身后。V1 架构让它在性能上追回了不少差距,而且 vLLM 的生态成熟度、API 兼容性(OpenAI 兼容 API)、社区规模仍然是它的护城河。对于很多团队来说,选择 vLLM 还是 SGLang,往往取决于具体的工作负载特征:高并发单轮生成更适合 vLLM,复杂多轮交互和结构化输出更适合 SGLang。
这两个项目的良性竞争,其实是整个 LLM 推理赛道的幸运。
写在最后
回过头来看,vLLM 最让我欣赏的一点,是它的核心创新并不来自某个全新的算法突破,而是把一个操作系统课本上几十年前就有的概念——虚拟内存与分页——重新应用到了 GPU 上的 KV Cache 管理。这种”跨领域搬运”的能力,往往比从零开始发明更需要洞察力。
当然,推理引擎的战争远没有结束。FlashAttention 持续迭代、FP8/FP4 量化逐渐成熟、Prefill-Decode 分离部署开始兴起……每一项技术都在重塑这个领域的格局。但不管接下来会发生什么,vLLM 用 PagedAttention 定义的这套”把 KV Cache 当内存来管理”的范式,大概率会作为这个时代推理优化的基石之一被记住。
如果你还没用过 vLLM,不妨去它的 GitHub 上看看。而如果你已经在用了,希望这篇文章能帮你更好地理解你手里这把工具的设计思路——知其然,也知其所以然。
发表回复