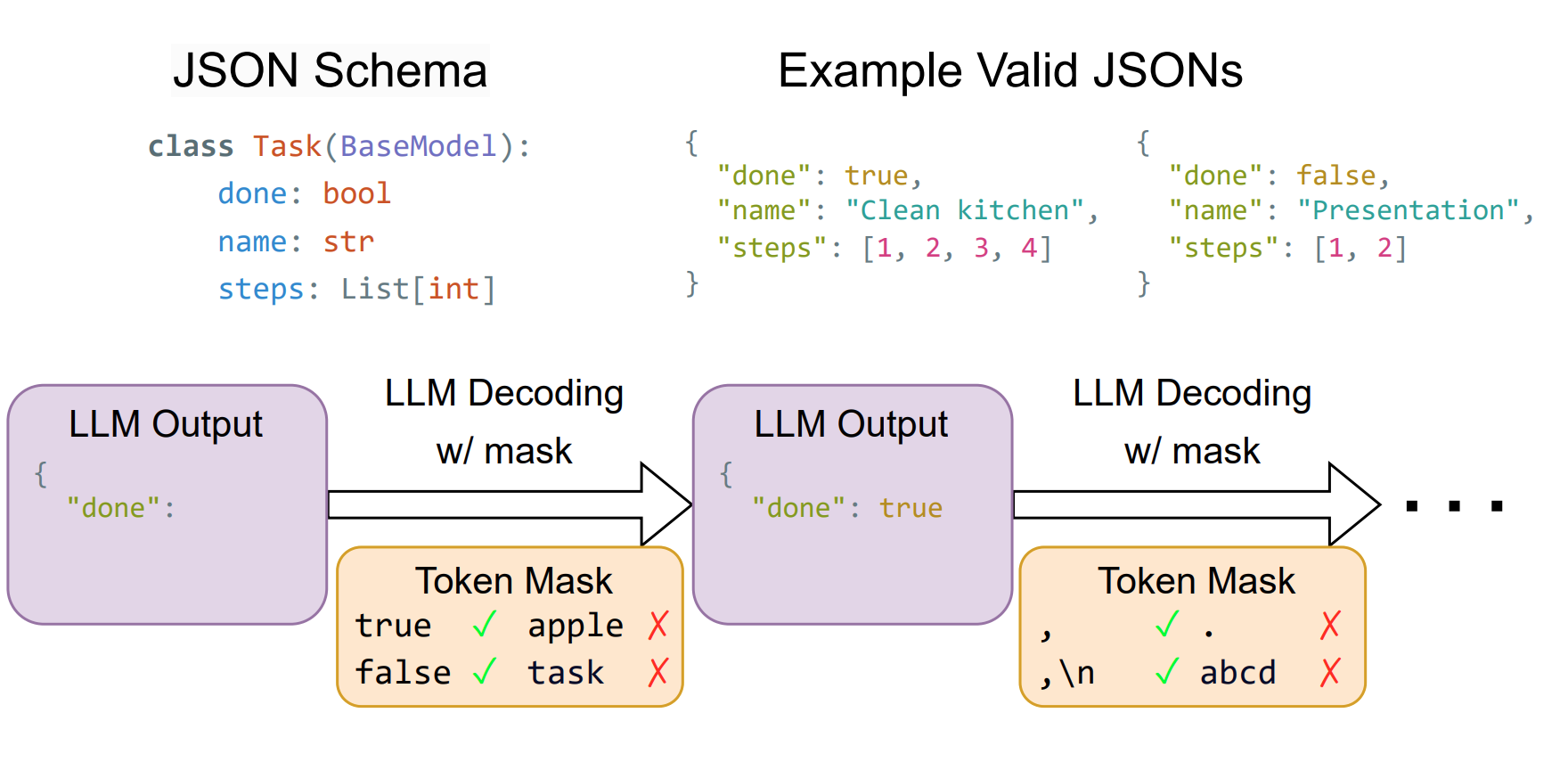
你可能已经在 OpenAI、Anthropic 或各种开源推理框架里见过这个功能了:给模型传一个 JSON Schema,模型就能乖乖返回一个完全符合你定义的 JSON 格式的响应。字段名对了,数据类型对了,该有的字段一个不少,不该有的字段一个不多。
这事看起来好像很理所当然——模型嘛,你告诉它按什么格式输出,它照做就行了。但如果你真的了解大语言模型的生成原理,就会知道这件事一点都不简单。一个靠「逐 token 采样」驱动的概率模型,凭什么能百分百输出合法的 JSON?Prompt 里写上”请用 JSON 格式回答”就够了吗?
答案是:远远不够。Structured Output 背后,藏着一套叫做「约束解码」(Constrained Decoding)的技术体系。这篇文章就来把这件事从头讲清楚。
模型生成文本的本质:逐 token 采样

理解 Structured Output 之前,必须先搞清楚大语言模型到底是怎么”写字”的。
LLM 是一个自回归(autoregressive)模型,它生成文本的方式是一个 token 接一个 token 往外蹦。每一步,模型会对词表中的所有 token 计算一个原始分数(logit),然后通过 softmax 把这些分数转换成概率分布,最后从这个分布里采样出下一个 token。主流模型的词表通常在 32,000 到 128,000 个 token 之间,意味着每一步都是从数万个候选里做选择。
正常情况下,这个采样过程是完全自由的——模型想输出什么就输出什么。这也是为什么模型擅长写散文、聊天、编故事,因为不受任何结构约束。但这种自由恰恰也是问题的根源:当你需要模型输出结构化数据的时候,它随时可能”犯错”。比如已经输出了 {"name": 之后,模型完全有可能接一个换行符而不是一个字符串值。它甚至可能忘记闭合大括号,或者凭空编造一个你 schema 里根本没有的字段名。
所以,想要可靠的结构化输出,光靠 prompt 提示是不够的。
JSON Mode:一次勇敢但不够的尝试
最早的尝试是 OpenAI 在 2023 年底推出的 JSON Mode。它的工作原理比较朴素:在系统提示中告诉模型「请用 JSON 格式回答」,然后在 API 层面保证模型的输出是一段合法的 JSON。
JSON Mode 确实做到了一件事——输出一定是可以被解析的 JSON。但它的局限性也很明显:它只保证”语法合法”,完全不保证”符合你的 schema”。你期望模型返回一个带 name、age、email 三个字段的对象,它可能给你返回一个只有 response 字段的 JSON。格式没错,内容全错。
在实际的生产环境中,这种”格式对了但结构不对”的输出几乎等于无效数据。你的下游程序期望从 JSON 里取出某个特定字段,结果字段压根不存在,程序直接崩溃。开发者们不得不加上各种兜底逻辑:校验返回格式、发现不对就重试、重试三次还不对就报错。这种”靠运气+重试”的模式,成本高,体验差,完全不工程化。
约束解码:从根源上解决问题
约束解码的思路完全不同:与其在模型输出之后再去校验和重试,不如在模型生成的过程中就把不合法的 token 给挡掉。
具体来说,约束解码在模型计算出 logit 之后、执行 softmax 采样之前,插入一个叫做「logit 处理器」(logit processor)的组件。这个组件会根据当前的生成状态,判断词表中哪些 token 是合法的续写,哪些会导致输出违反目标结构。对于那些不合法的 token,直接把它们的 logit 设为负无穷大(-∞),这样经过 softmax 之后它们的概率就变成了零,模型永远不会采样到它们。
举个简单的例子。假设你的 schema 要求输出一个对象,现在模型刚刚生成了 {"id": ,那么下一个 token 应该是一个数字。此时,logit 处理器会把词表里所有字符串 token、布尔值 token、括号 token 全部屏蔽掉,只留下数字相关的 token 供模型选择。模型原来的概率偏好在合法 token 之间依然保持——如果它更倾向于输出 42 而不是 7,这个偏好会被保留——但绝对不可能输出一个违反格式的东西。
这种方法有几个关键优势。首先是零重试:因为每一步只能生成合法 token,最终输出一定符合目标结构,不需要任何后处理或重试逻辑。其次是零额外成本:和重试方案不同,约束解码不会多消耗任何推理计算,token 用量基本不变。实际上,由于模型不再输出多余的寒暄语和格式说明文字,总输出长度往往比自由生成更短。
那么关键问题来了:这个 logit 处理器怎么知道在每一步哪些 token 是合法的?
有限状态机:把文法变成路线图
2023 年,Brandon Willard 和 Rémi Louf 发表了论文《Efficient Guided Generation for Large Language Models》,提出了一个极其优雅的洞察:自回归文本生成可以被重新表述为有限状态机(Finite State Machine, FSM)的状态转移。
什么意思呢?假设你有一个正则表达式 [0-9]*\.?[0-9]*,用来匹配浮点数。这个正则表达式可以被编译成一个确定有限自动机(DFA),它有一组状态和状态之间的转移规则。从起始状态开始,每消费一个合法字符,就跳转到下一个状态;如果到达某个终止状态,说明整个字符串匹配成功。
Willard 和 Louf 的关键创新在于:他们把 DFA 的字母表从「字符」替换成了「token」。也就是说,他们构建了一个 token 级别的 DFA,其中每个状态对应的合法转移不再是单个字符,而是 LLM 词表中的 token。一个 token 可能包含多个字符(比如 42 是一个 token,.2 也可能是一个 token),所以从一个 DFA 状态出发,一个 token 可能一次跨越多个字符级别的状态转移。
这个方案最精妙的地方在于「预计算」。给定一个正则表达式(或者 JSON Schema 编译出来的正则表达式)和一个 tokenizer 的词表,你可以在推理开始之前,预先计算出每个 FSM 状态下所有合法 token 的集合。这就形成了一个索引表:状态 → {合法 token ID 集合}。推理时,只需要查这张表就行了,不用每一步都重新遍历词表去判断合法性。
预计算的成本只在编译阶段支付一次,之后所有使用同一个 schema 的生成请求都可以复用。这使得约束解码在推理时的额外开销非常小——在最优实现中,每个 token 的掩码生成时间可以低到 40 微秒以下。
这个方案被实现为开源库 Outlines,迅速成为了约束解码领域最有影响力的工具。
正则表达式的天花板:递归结构怎么办?
基于有限状态机的方案优美且高效,但它有一个计算理论层面的根本限制:有限状态机只能表达正则语言(regular language),而 JSON 是一种递归语言——对象可以嵌套对象,数组可以包含数组,嵌套深度没有上限。
用一个具体场景来说明:假设你定义了一个递归类型,比如一棵树的节点,每个节点有一个 value 字段和一个可选的 children 数组,而 children 里的每个元素又是同一种节点类型。这种递归结构,理论上不可能用正则表达式完全描述——你无法用有限状态来追踪无限深度的嵌套和括号匹配。
在实际操作中,Outlines 的做法是把 JSON Schema 先转换成正则表达式,这意味着递归结构要么被展开到固定深度(比如最多嵌套 5 层),要么干脆不支持。这对简单的、扁平的 schema 够用了,但面对复杂的业务场景就力不从心。
解决这个问题需要从有限状态机升级到更强大的自动机模型。
下推自动机:用栈来追踪嵌套
2024 年底,来自 CMU 和 NVIDIA 的团队推出了 XGrammar,通过引入下推自动机(Pushdown Automaton, PDA)来解决递归问题。
下推自动机和有限状态机的区别在于,它多了一个「栈」(stack)。你可以把它理解成一组有限状态机的集合:每个语法规则对应一个 FSM,当一个规则引用了另一个规则时,PDA 就把当前规则的状态压入栈中,跳转到被引用的规则去继续匹配;等被引用的规则匹配完毕,再从栈中弹出之前的状态,回到原来的位置继续。这种”压栈-弹栈”的机制天然适合处理递归和嵌套结构。
但 PDA 也带来了新的工程挑战。FSM 的状态是有限的,所以可以预计算每个状态的合法 token 掩码。PDA 的状态则包含了栈的内容,而栈的深度是无限的,理论上有无穷多种可能的状态——你没法为每种状态都预计算掩码。
XGrammar 的核心洞察在于:虽然不能预计算所有状态的掩码,但绝大多数 token(通常超过 99%)的合法性其实只取决于 PDA 当前所在的节点,跟栈里存了什么无关。XGrammar 把 token 分成了两类:「上下文无关 token」——只看当前节点就能判断合法性的,预计算存进缓存里;「上下文相关 token」——需要看栈内容才能判断的,在运行时动态计算。因为后者通常不到 token 总量的 1%,所以运行时的计算开销极小。
加上一系列从编译器优化技术中借鉴来的手段——PDA 节点合并、并行语法编译、将语法处理和 GPU 推理流水线化重叠执行——XGrammar 实现了接近零开销的约束解码。在 JSON 任务上,比传统方案快了两个数量级。到 2025 年初,vLLM 和 SGLang 这两个主流推理框架都已经将 XGrammar 作为默认的约束解码后端。
OpenAI 的路线:上下文无关文法
值得一提的是 OpenAI 在 2024 年 8 月推出 Structured Outputs 时采用的技术路线。OpenAI 明确表示,他们使用的是基于上下文无关文法(Context-Free Grammar, CFG)的约束采样,而不是有限状态机方案。
OpenAI 给出的理由是:CFG 能表达的语言类比 FSM 更广。对于简单的扁平 schema,两者效果差不多;但对于涉及嵌套和递归的复杂 schema,FSM 可能力不从心,而 CFG 天然能处理括号匹配和深层嵌套。OpenAI 在博客中给出了一个递归类型的例子:一个数学表达式的 schema,表达式可以是数字、也可以是两个表达式做运算,这种结构用 FSM 无法表示,但 CFG 可以轻松描述。
2025 年 5 月,OpenAI 公开致谢了 Microsoft 的 llguidance 库——一个用 Rust 编写的约束解码引擎——称其为 Structured Outputs 实现的基础。llguidance 使用基于导数的正则引擎做词法分析,用优化过的 Earley 解析器处理 CFG 规则,对 128K 词表的模型每个 token 的处理时间大约在 50 微秒。
一个容易被忽视的细节:token 边界的诅咒
在约束解码的实际工程中,有一个极其微妙的问题会影响输出质量,那就是 tokenization 边界。
现代 LLM 使用子词分词器(subword tokenizer),比如 BPE。BPE 的一个特性是:同一段文本,如果分词的起始位置不同,可能会产生不同的 token 序列。而约束解码会在模型的采样过程中强制选择某些 token,有时候会把模型推上一条「非典型分词路径」——也就是训练时很少见到的 token 序列。
Microsoft 的 Guidance 库最早揭示了这个问题,并提出了一个叫做 Token Healing 的方案。举一个经典的例子:当 prompt 以 http: 结尾时,GPT-2 模型不会在后面接上 // 来形成一个完整的 URL。为什么?因为在训练数据中,:// 通常是一个完整的 token(ID 1358),但 prompt 的分词把 : 单独切成了一个 token(ID 27)。模型看到独立的 : 之后,它的隐含信息是”后面不太可能是能和冒号合并的内容”——于是模型倾向于输出一个空格而不是双斜杠。
Token Healing 的解法是:在生成开始时,往回退一个 token,然后约束第一个生成的 token 必须以被退回的 token 文本开头。这样就让模型有机会选择一个更自然的、跨越原始 prompt 边界的 token,恢复到训练时更常见的分词方式。
在约束解码的场景下,这个问题更加突出,因为 logit 掩码不断改变模型的采样路径,可能频繁产生非典型分词。如果不处理好这个问题,模型输出的 JSON 虽然结构合法,但内部的值可能质量下降——措辞不自然、推理链断裂,甚至出现语义错误。
结构化输出也有代价:被拴住的推理能力
约束解码保证了 100% 的结构正确性,但它有一个被研究证实的副作用:可能损害模型的推理能力。
2024 年,Tam 等人发表了一篇题为”Let Me Speak Freely?”的论文,系统性地测试了格式约束对 LLM 性能的影响。实验发现,在数学推理等需要复杂思维链的任务上,严格的 JSON Mode 显著降低了模型的准确率。比如 GPT-3.5-turbo 在 GSM8K 数学题上,自然语言回答能答对的题目,切换到 JSON 格式后就答错了。
降级背后的原因和模型的自回归生成方式有关。LLM 是一个 token 一个 token 往前生成的,前面生成的内容会影响后面的推理。当你用 JSON Schema 强制模型先输出某些字段时,可能会迫使模型在还没完成推理之前就给出答案——因为答案字段排在推理字段前面。模型没有机会”先想清楚再回答”。
这个发现引出了一条重要的最佳实践:在设计 JSON Schema 时,应该把推理过程(如 explanation、reasoning)放在结果字段(如 answer、result)之前。这个字段顺序在自由文本中无所谓,但在结构化输出中至关重要,因为它决定了模型的”思考顺序”。
不过,这项研究也发现了一个有趣的反面效果:在分类任务上,JSON Mode 反而提升了准确率。格式约束把可能的输出空间收窄了,减少了模型在答案选择上的犹豫和错误,相当于给分类器加了一道”只能从这几个选项里选”的硬约束。
所以总结起来,约束解码对推理密集型任务有负面影响,但对分类和提取类任务有正面影响。该不该用、怎么用,取决于你的具体场景。
当前的技术格局
约束解码在短短两三年内从学术论文发展到了全面的工业部署。目前的技术格局大致可以从几个维度来理解。
在云端 API 方面,OpenAI 的 Structured Outputs 是最早也最成熟的产品化实现,使用 CFG 方案,要求 schema 中所有对象必须设置 additionalProperties: false 且所有属性都标记为 required。Google 的 Gemini 通过 Function Calling 支持结构化输出。Anthropic 的 Claude 也在跟进这一方向。
在开源推理框架方面,vLLM 和 SGLang 是两个主力,它们都以 XGrammar 作为默认后端。vLLM 同时还支持 Outlines 和 lm-format-enforcer 作为备选后端。这些框架通过 guided_json、guided_regex、guided_grammar 等参数,让开发者可以灵活选择约束方式——从简单的多选约束、正则表达式匹配,到完整的 JSON Schema 和自定义上下文无关文法,一应俱全。
在更高层的应用封装方面,Instructor 库提供了一个便捷的接口,让开发者直接用 Pydantic 模型定义 schema,库内部自动处理和各个 API 提供商之间的对接。Python 的 Pydantic 模型和 TypeScript 的 Zod 模型已经成了定义结构化输出的事实标准工具。
几个实用的注意事项
在实际使用结构化输出时,有几件事值得留意。
首先是 Schema 的复杂度问题。嵌套层级太深、枚举值太多、oneOf 分支太复杂的 schema,会显著增加语法编译时间和每个 token 的处理开销。尽量保持 schema 扁平,能用简单结构表达的就不要用复杂结构。
其次是字段描述不要偷懒。Pydantic 模型中的 Field(description=...) 或者 JSON Schema 中的 description 字段,会被传递给 LLM 作为内联指令。省略这些描述会迫使模型完全靠字段名来猜语义,效果自然打折扣。
再次是不要混淆 JSON Mode 和 Structured Outputs。前者只保证输出是合法 JSON,后者才保证符合 schema。如果你的 API 提供商支持 Structured Outputs,就不要退而求其次地用 JSON Mode。
最后,结构合法不等于语义正确。约束解码能保证模型输出的 JSON 格式完美,但不能保证里面的值是对的。模型可能在 confidence 字段里填 0.99、在 category 字段里选一个完全不搭的类别。结构化输出防的是格式错误,不是内容错误。
结语
从”在 prompt 里写一句’请用 JSON 格式回答’”到基于上下文无关文法的约束解码,结构化输出的演进路径清晰地展示了一个规律:当 LLM 需要和真实世界的软件系统集成时,概率生成的”大约对”是远远不够的,我们需要的是形式化保证的”一定对”。
约束解码通过在每个 token 的生成步骤中嵌入形式语言理论的武器——有限状态机、下推自动机、上下文无关文法——把一个原本不可靠的文本生成过程,变成了一个可验证、可信赖的结构化数据生产过程。这项技术让 LLM 从一个”会聊天的 AI”真正升级成了可以嵌入软件流水线的”可编程组件”。
当然,正如我们讨论的那样,这种可靠性也有代价。字段顺序会影响推理质量,分词边界会引入微妙的偏差,过度严格的格式约束可能会压缩模型的思考空间。理解这些权衡,才能在实际项目中做出合理的设计决策。
发表回复