用过大模型 API 的人,多多少少都见过这两个参数——Temperature 和 Top-P。界面上通常是两根滑块,默认值看起来挺合理,很多人拖一拖、试一试,觉得”好像变了点什么”,然后就这么糊弄过去了。
但这两个数字到底在干什么?为什么调高 Temperature 回答就”飘”了,调低又变得”死板”?Top-P 和 Temperature 到底是一回事还是两回事?
今天就把这事儿掰开了聊。
先从大模型怎么”说话”讲起
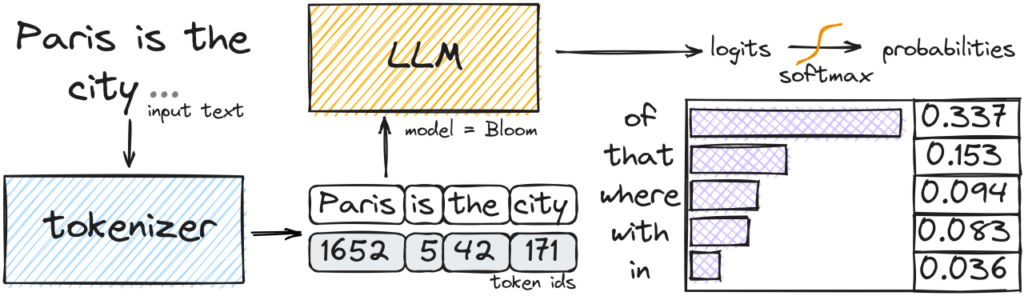
要理解这两个参数,得先知道大模型生成文字的基本原理。
大模型的工作方式是一个字一个字地往外蹦——准确说是一个 token 一个 token 地往外蹦。每一步,模型都会面对词表里几万甚至十几万个候选 token,然后给每个 token 打一个分数。这些分数叫做 logits,是一组原始的数值,有正有负,数值越高代表模型觉得这个词越应该出现在当前位置。
但 logits 本身没法直接用来做选择,因为它们不是概率——它们可以是任意大小的数字,加起来也不等于 1。所以下一步是把这些 logits 通过一个 softmax 函数转换成概率分布:每个 token 对应一个 0 到 1 之间的数字,所有 token 的概率加起来等于 1。
然后,模型就从这个概率分布里”抽签”,选出下一个 token。概率高的被抽中的可能性大,概率低的也不是完全没机会。
整个生成过程就是不断重复这个循环:算 logits → 转概率 → 抽一个 token → 接到已有文本后面 → 再算下一轮。
Temperature 和 Top-P,就是在”转概率”和”抽签”这两个环节上动手脚的。
Temperature:控制概率分布的”陡峭程度”
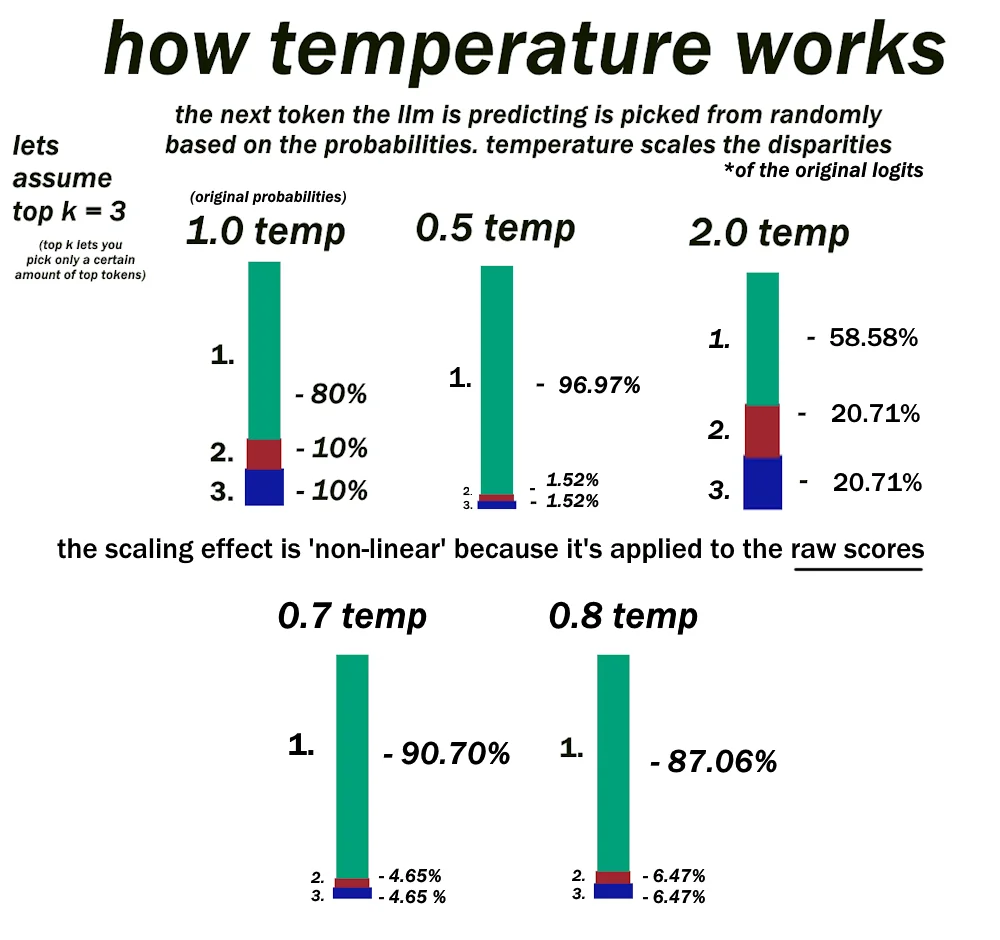
Temperature 的作用发生在 softmax 之前。原本 softmax 是直接把 logits 转成概率的,但加了 Temperature 之后,会先拿 logits 除以一个值 T(也就是 Temperature),然后再做 softmax。
就这么一除,效果天差地别。
当 T < 1 的时候,相当于把 logits 放大了。原本差距不大的分数,经过放大后差距变得更悬殊。softmax 一算,高分的 token 概率变得更高,低分的被压得更低。结果就是模型几乎总是选那个”最有可能”的词,输出变得稳定、可预测,但也更无聊。
当 T > 1 的时候,等于把 logits 缩小了。原来有明显高低之分的分数被”拉平”了,softmax 出来的概率分布变得更均匀。于是那些本来没什么机会的 token 也开始有了被选中的可能,输出变得多样、出人意料——当然也更容易胡说八道。
当 T = 1 的时候,什么都没变,就是标准的 softmax。
用一个直觉性的比喻来说:Temperature 就像是给模型灌酒。T 小的时候,模型是清醒的,说话谨慎、有条理;T 大了,模型开始上头,话越来越野、越来越飘。T 要是特别大,那就是烂醉如泥,开始胡言乱语。
举个具体的例子。假设模型对下一个词只有三个候选:A(logit=4)、B(logit=2)、C(logit=1)。在标准 softmax(T=1)下,A 的概率大约 84%,B 大约 11%,C 大约 4%。模型大概率会选 A。但如果你把 Temperature 调到 2,概率就变成了 A 大约 58%,B 约 23%,C 约 18%。B 和 C 被选中的机会大大增加了。反过来,如果 T 调到 0.5,A 的概率会被推到 97% 以上,基本上是铁板钉钉选 A。
当 T 趋近于 0 的时候,效果就相当于”贪心解码”——永远选概率最高的那个,完全确定性的输出。
Top-P:动态裁剪候选池
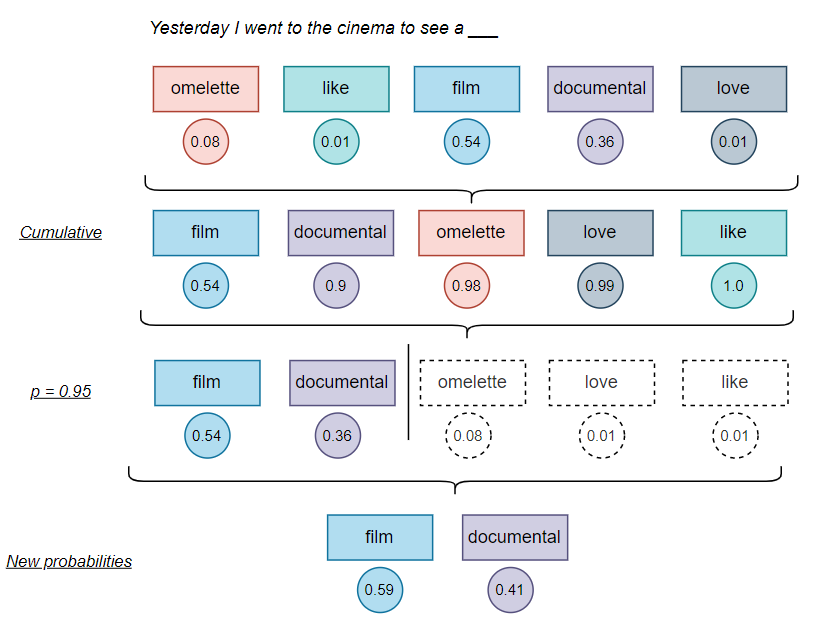
Top-P(也叫核采样,Nucleus Sampling)的思路不太一样。它不去动概率分布的形状,而是在采样之前,先砍掉一批候选 token。
具体做法是:把所有 token 按概率从高到低排好,然后从最高的开始往下累加,当累计概率达到 P 这个阈值时,就停下来。剩下的那些概率太低的 token 直接淘汰,不参与抽签。然后在保留下来的这个小集合里重新归一化概率(让它们重新加起来等于 1),再从中采样。
Top-P 接近 1(比如 0.95) 的时候,几乎整个词表都被保留了,效果和不做裁剪差不多,输出偏多样。
Top-P 比较小(比如 0.1) 的时候,只有概率最高的那几个 token 被留下来,输出非常集中、确定。
Top-P 有个很妙的特性:它是自适应的。如果模型在某一步非常自信,一个 token 的概率就高达 90%,那 Top-P=0.95 的情况下可能只保留两三个 token。但如果模型很纠结,概率分布比较平坦,同样的 Top-P 值可能会保留几十个 token。它会根据模型自身的”信心程度”自动调整候选池的大小。
这和 Top-K 不同——Top-K 是固定选前 K 个,不管概率分布长什么样。Top-P 则更灵活,更能适应不同语境下模型的状态。
Temperature 和 Top-P 的区别与配合
一句话总结两者的区别:Temperature 改变概率分布的形状,Top-P 改变参与采样的 token 数量。
Temperature 像是在调一个”旋钮”,让整个概率分布要么尖峭要么平坦。Top-P 像是在画一条”截止线”,把不够格的 token 排除在外。
两者可以组合使用,但很多业内人士和模型提供商给出的建议是:一般只调其中一个,另一个保持默认值。同时大幅调整两者可能产生难以预测的效果——比如高 Temperature 配低 Top-P,你既在”拉平”概率又在”砍人”,最终效果取决于两者的相互角力,调试起来很头疼。
常见的实用搭配大致是这样:
对于事实性问答、代码生成、翻译这类需要准确性的任务,Temperature 低一点(0.1 ~ 0.3),Top-P 可以保持在 0.9 左右。对于创意写作、头脑风暴、故事生成这类需要多样性的场景,Temperature 可以调高到 0.7 ~ 1.0,或者把 Top-P 设低一些来控制不要太离谱。
不过说到底,没有放之四海而皆准的”最佳参数”。不同的模型对同样的参数值反应也不同——在一个模型上 0.7 刚刚好的设置,换到另一个模型上可能就太激进了。唯一靠谱的办法就是:试。一次只调一个参数,看看效果,慢慢逼近你想要的平衡点。
一些容易踩的坑
最后聊几个常见的误解。
第一,Temperature 不会让模型变聪明或变笨。它不改变模型内部的知识或推理能力,只是改变了模型在做选择时的”冒险程度”。调高 Temperature 不是在激发创造力,而是在增加随机性——有时候随机性恰好带来了惊喜,有时候带来的就是垃圾。
第二,Temperature = 0 在理论上意味着完全确定性输出,但实际实现中可能并非如此。由于浮点数精度问题,有些框架在 T=0 时的表现可能存在细微差异。
第三,不同的推理框架对参数的处理顺序可能不同。有的框架先做 Temperature 缩放再做 Top-P 裁剪,有的反过来。同样的参数值在不同后端上可能产生不同的输出,切换框架时务必重新测试。
第四,调低 Temperature 不能解决幻觉问题。模型编造信息(hallucination)是模型本身能力和训练数据的问题,不是采样策略能根治的。低 Temperature 只是让模型更倾向于选那个”最可能”的答案,但如果模型”真心觉得”一个错误答案概率最高,那低温照样会输出错误。
写在最后
Temperature 和 Top-P 本质上都是在回答同一个问题:模型选下一个词的时候,应该多大胆?
Temperature 通过重塑概率的地形来回答这个问题——要么把山峰削平让大家机会均等,要么把山峰堆得更高让赢家通吃。Top-P 则是直接划一条及格线——达不到门槛的,连参与竞争的资格都没有。
理解了这些,你下次调参数的时候就不再是盲人摸象了。虽然最终还是得靠实验来确定最佳值,但至少你知道自己在拧的是哪个旋钮,以及拧动之后会发生什么。
这可能是跟大模型打交道时,最值得搞懂的两个数字了。
发表回复