在聊 MoE 之前,得先理解它要替代的东西。
传统的大语言模型,比如早期的 GPT 系列,用的是所谓的”稠密”(dense)架构。每一个 token 进来,都要经过模型的全部参数。你问它一道数学题,全部参数参与计算;你让它写一首诗,还是全部参数参与计算。就好比那个咨询公司里只有一个人,不管什么问题都得他来答,他得同时是律师、会计师和程序员。
这个做法的问题显而易见:想让模型更聪明,就得加更多参数;参数越多,计算量越大,推理越慢,训练越贵。你想把模型从 70 亿参数扩展到 7000 亿参数,计算成本也会相应暴增。模型的”容量”和”计算开销”被死死绑在了一起。
MoE 的核心思路,就是把这两件事解绑。
拆开来看,MoE 到底改了什么
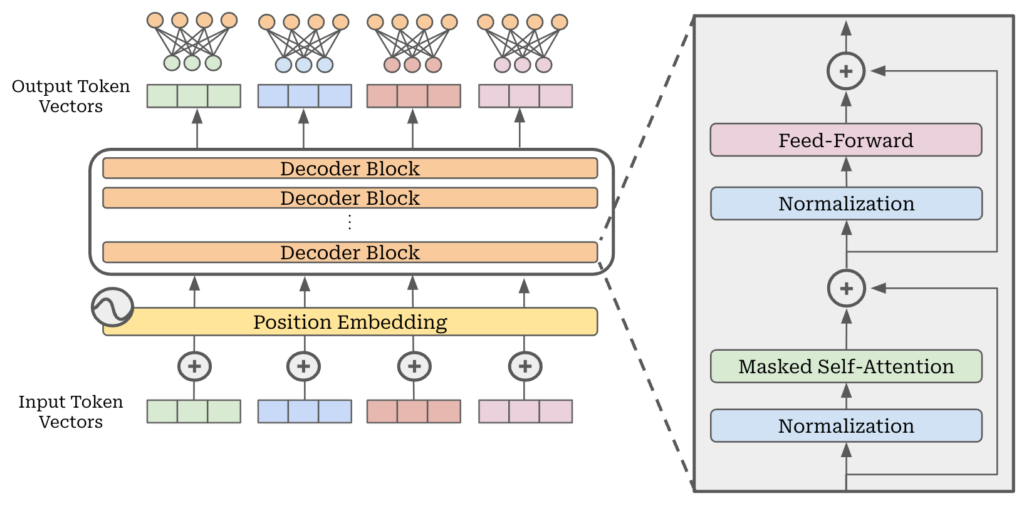
要理解 MoE 的架构改动,需要先知道 Transformer 里的一个关键组件:前馈神经网络(Feed-Forward Network, FFN)。在标准的 Transformer 结构中,每一层都包含两个主要部分——注意力机制(Attention)和前馈网络。注意力机制负责让 token 之间互相”交流”,搞清楚上下文关系;前馈网络则负责对每个 token 独立做更深层的特征变换。
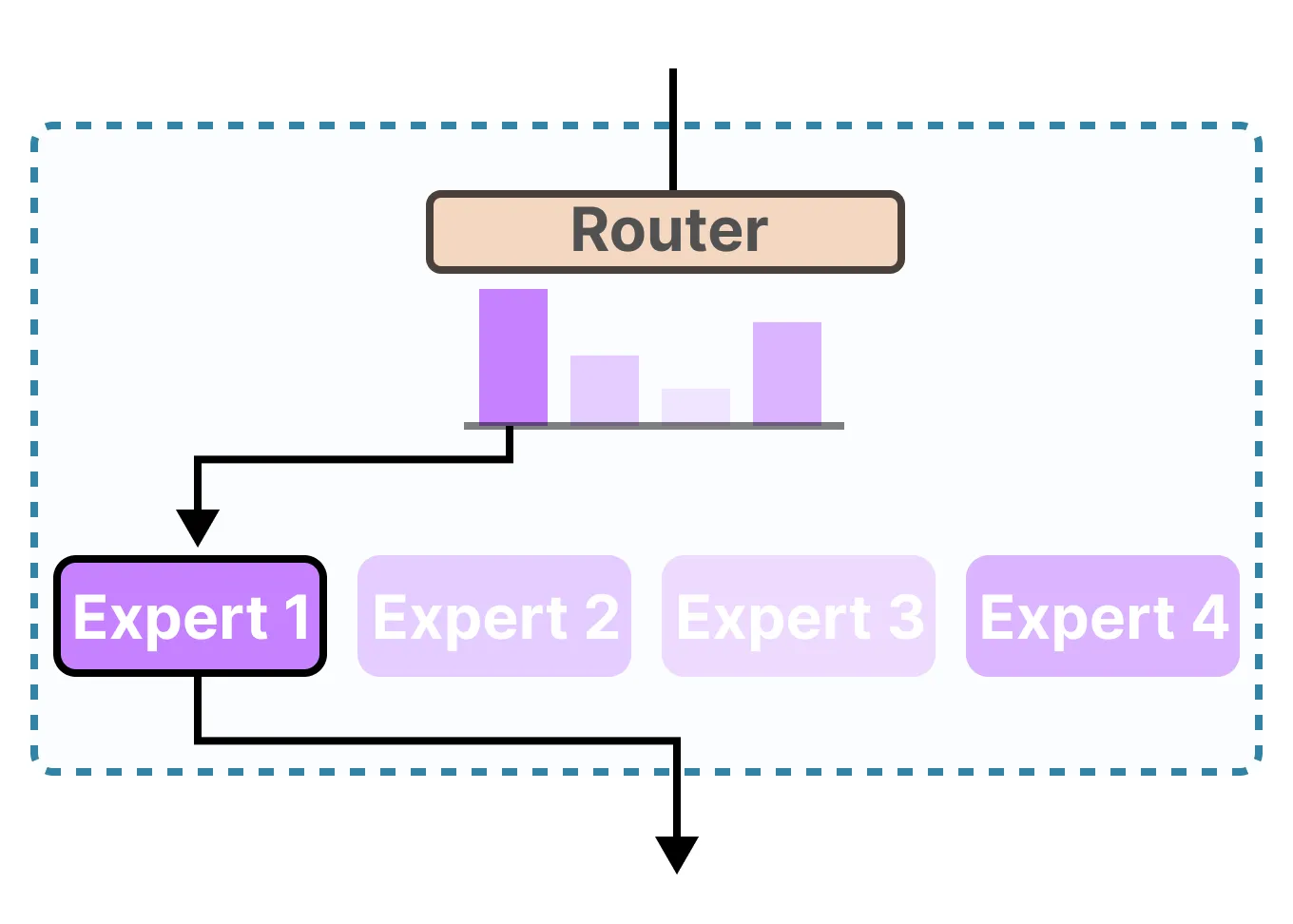
MoE 改动的就是后者。它把原本那一个大的前馈网络,替换成了一组更小的前馈网络,也就是所谓的”专家”(experts)。同时,它在这些专家前面加了一个”路由器”(router,也叫 gating network),由路由器来决定当前这个 token 该被送到哪个或哪几个专家那里去处理。
举个具体的例子。DeepSeek-V3 这个模型,总共有 6710 亿个参数,但每个 token 只激活其中大约 370 亿个。它的每一层 MoE 里有 256 个路由专家和 1 个共享专家,每个 token 会被路由到其中 8 个专家进行处理。换句话说,虽然模型很大,但任何时刻真正在干活的只是很小一部分。
这就是 MoE 最根本的价值所在:模型的总容量可以做得很大(参数多,能记住更多知识),但实际的计算开销可以保持在较低水平(每次只用一小部分参数)。
路由器:整个系统里最关键的角色
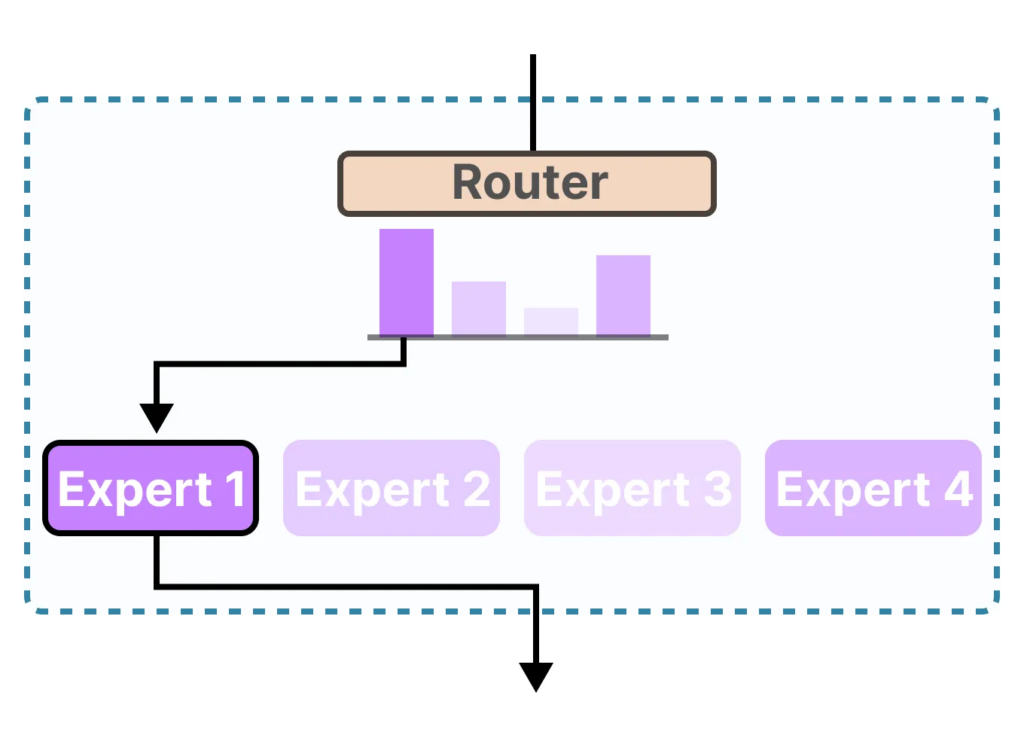
如果说专家是干活的人,路由器就是分配任务的调度员。它的工作看似简单——给每个 token 选几个合适的专家——但实际上,路由器的好坏直接决定了整个 MoE 系统的成败。
路由器本身通常就是一个很小的网络,甚至可能只是一个线性层。它接收 token 的表示向量作为输入,输出一组分数,每个专家对应一个分数。然后取分数最高的 Top-k 个专家来处理这个 token。
听起来很简单,对吧?但这里面暗藏着一个经典的矛盾。
一方面,你希望路由器能够”聪明地”把不同类型的 token 分配给不同的专家,让每个专家都能发展出自己的专长——这叫专家专业化(expert specialization)。另一方面,你又不希望路由器太偏心,总把 token 都往少数几个专家那里送,导致有些专家忙得不可开交、有些专家无所事事——这叫负载均衡(load balancing)。
如果负载严重不均衡,极端情况下会发生”路由坍塌”(routing collapse):路由器学会了把所有 token 都送给同一个或少数几个专家,其余专家形同虚设。这时候你的 MoE 模型本质上就退化成了一个小得多的稠密模型,白白浪费了那些闲置的参数。
早期的做法是引入一个辅助损失函数(auxiliary loss),在训练时额外惩罚负载不均衡的情况。但这个损失如果加得太重,又会干扰模型真正想学的东西,导致性能下降。DeepSeek-V3 提出了一种不依赖辅助损失的负载均衡策略,通过给每个专家引入一个可调节的偏置项来动态调整路由倾向,在保持负载均衡的同时尽量不损害模型性能。
路由机制的设计至今仍是 MoE 研究中最活跃的领域之一。从最简单的哈希路由(根据 token ID 直接分配,简单但效果差),到基于学习的 Top-k 路由(主流方案),再到”让专家来选 token”的 Expert Choice 路由(由 Google 提出,反过来让每个专家挑选自己最想处理的 token),研究者们一直在寻找那个同时兼顾专业化和均衡性的甜蜜点。
“专家”到底在专什么
这里有一个常见的误解需要澄清。
很多人听到”专家”这个词,会直觉地以为一个专家负责心理学、一个专家负责生物学、一个专家负责编程。这个想象很美好,但实际情况并非如此。
MoE 中的专家专业化,更多发生在语言的语法和结构层面,而不是语义和知识领域层面。一个专家可能擅长处理某种特定的句法模式,另一个专家可能更善于处理数字相关的 token,还有一个专家可能对特定语言或文本风格更敏感。这种分工是在训练过程中自然涌现出来的,没有人预先指定谁负责什么。
训练过程中会形成一个有趣的正反馈循环:一个专家在处理某类 token 时表现稍好一点 → 路由器学会把更多类似的 token 发给它 → 它在这类 token 上获得了更多训练 → 它变得更擅长处理这类 token → 路由器更倾向于选择它。如此循环往复,专业化就自然而然地形成了。
不过,这种自然涌现的分工也带来了一个问题:专家之间可能会出现大量重叠。不同的专家可能学到了非常相似的表示,造成了参数的冗余浪费。这也是为什么最近的研究开始引入专门的损失函数来鼓励专家之间的差异化——比如惩罚不同专家在处理同一个 token 时产生过于相似的激活模式。
为什么现在所有前沿模型都在用 MoE
2025 年以来,几乎所有顶尖的大语言模型都采用了 MoE 架构。在独立评测排行榜上,排名前十的开源模型全部使用 MoE。DeepSeek-R1、Kimi K2、Mistral Large 3、GPT-5(据报道也使用了 MoE)——这些名字背后都有 MoE 的身影。
原因很直接:MoE 让”又大又快”成为可能。
一个 6710 亿参数的 MoE 模型,实际推理时的计算量可能只相当于一个 370 亿参数的稠密模型。但它拥有的知识容量远超后者。DeepSeek-V3 的训练成本大约是 560 万美元(约 278.8 万 H800 GPU 小时),而训练一个同等性能的稠密模型,成本可能是它的十倍甚至更多。
MoE 的另一个优势在于它天然适合分布式部署。既然模型已经被拆成了多个专家,那就可以很自然地把不同的专家放到不同的 GPU 上,实现专家并行(expert parallelism)。NVIDIA 的 NVLink 技术让不同 GPU 上的专家可以高速通信,进一步释放了 MoE 的部署潜力。
从某种意义上说,MoE 的走红是一种必然。当稠密模型的规模触碰到算力和成本的天花板时,MoE 提供了一种在不成比例增加计算开销的前提下继续扩大模型容量的路径。
MoE 面临的挑战
当然,MoE 也有它的代价。
首先是内存压力。虽然每次推理只用一小部分参数,但所有专家的权重都需要加载到内存中。一个拥有 256 个专家的模型,即便每次只激活 8 个,你仍然需要为全部 256 个专家预留显存空间。这使得 MoE 模型的部署门槛比同等激活参数量的稠密模型要高得多。
其次是训练的不稳定性。路由机制的引入给训练增加了额外的复杂度。路由坍塌、专家利用率不均、梯度消失——这些问题在 MoE 训练中都更容易出现。调参经验和稠密模型也有所不同,比如 MoE 模型通常更适合较小的 batch size 和较高的学习率。
最后是微调的特殊性。由于 MoE 模型中大约 80% 的参数都在专家层(以 ST-MoE 的数据为例),而每个 token 只会经过其中少数几个专家,直接更新所有参数的效率并不高。研究表明,冻结 MoE 层只更新其余参数,效果几乎一样好。这意味着微调 MoE 模型需要一套不同于稠密模型的策略。
写在最后
MoE 的核心理念,说到底就是一句话:不是每个问题都需要动用所有的知识。
这个理念本身甚至算不上多么新颖。早在 1991 年,Jacobs 等人就在论文中提出了”自适应局部专家混合”的想法。三十多年过去了,这个想法终于在大语言模型的时代找到了它的用武之地,并且迅速成为了行业的主流选择。
如果你今天在使用任何一个前沿 AI 模型,无论是写代码还是聊天,大概率都有一个路由器在幕后默默工作,在几百个专家中快速挑选出最合适的几个来处理你的每一个字。你看不到这个过程,但你能感受到它的结果——模型又大又快,又便宜又聪明。
这就是 MoE 在做的事。
发表回复