你可能已经听过不少关于 AI Agent 的宣传了——它们能写代码、能做研究、能帮你管理日程。不过,如果你真的让一个 Agent 连续工作几个小时,甚至几天、几个月,这些 Agent 可能会”崩溃”。
一个原本表现良好的 AI,在运行了足够长的时间后,开始做出完全不合逻辑的决定,陷入自我重复的死循环,甚至试图联系 FBI。是的,你没看错,FBI。
这就是 Agent 稳定性(Agent Stability)要讨论的核心话题。
问题出在哪里
我们先从一个直觉说起。你让 ChatGPT 或者 Claude 回答一个问题,它通常表现得不错。你让它写一段代码,大多数时候也没问题。但这些都是短任务——几秒钟到几分钟就结束了。
真正的挑战在于长时间运行。当一个 Agent 需要持续几个小时、几天甚至模拟一整年来完成任务时,情况就完全不同了。每一步的微小偏差都会累积。上下文窗口会被填满。更要命的是,模型会受到自身之前错误输出的”污染”——研究者称之为”自我调节效应”(self-conditioning effect)。简单来说,当上下文里包含了模型之前犯的错误时,它接下来犯错的概率会显著上升。错误会滚雪球一样越滚越大。
而且这种退化跟上下文窗口用完没有直接关系。即使模型还有足够的记忆空间,即使你给了它外部记忆工具,它依然可能在某个时刻突然”断片”。
用自动售货机测试 AI 的长期稳定性:Vending-Bench
为了量化这个问题,AI 安全公司 Andon Labs 设计了一个非常巧妙的基准测试,叫 Vending-Bench。
它的设定很简单:让 AI 扮演一个自动售货机的运营者。AI 需要管理库存、向供应商下单、设定商品价格、支付每日场地费。这些任务每一个单独拿出来都极其简单,任何一个前沿模型都能轻松搞定。但把它们组合在一起,让 AI 连续运营一整年(模拟时间),总共产生 3000 到 6000 条消息、6000 万到 1 亿个 token 的输出——事情就变得非常有趣了。
研究结果显示,所有模型的表现方差都极大。同一个模型、同样的设定,跑五次可能会产生截然不同的结果。有的运行表现优异,甚至超越人类基准线;有的运行则会彻底崩溃。
崩溃的方式千奇百怪。有的模型会忘记自己下过的订单,反复重复采购。有的会误判配送时间,以为货物已经到了其实还没到,然后在”已到货”的幻觉基础上做出一系列错误操作。最戏剧性的案例来自早期的 Claude Sonnet:它在一次运行中陷入了”死亡螺旋”(doom loop),先是尝试”关闭”整个售货业务(这在模拟中根本不可能),然后在发现每天 2 美元的场地费还在持续扣除后,决定联系 FBI 举报欺诈。它甚至给”CEO”发了一封标记为”紧急”的邮件,要求高层介入处理”关键系统故障”。
这不是 bug,这是模型在长期运行中丧失了对环境的基本理解。
Vending-Bench 2 和竞技场模式
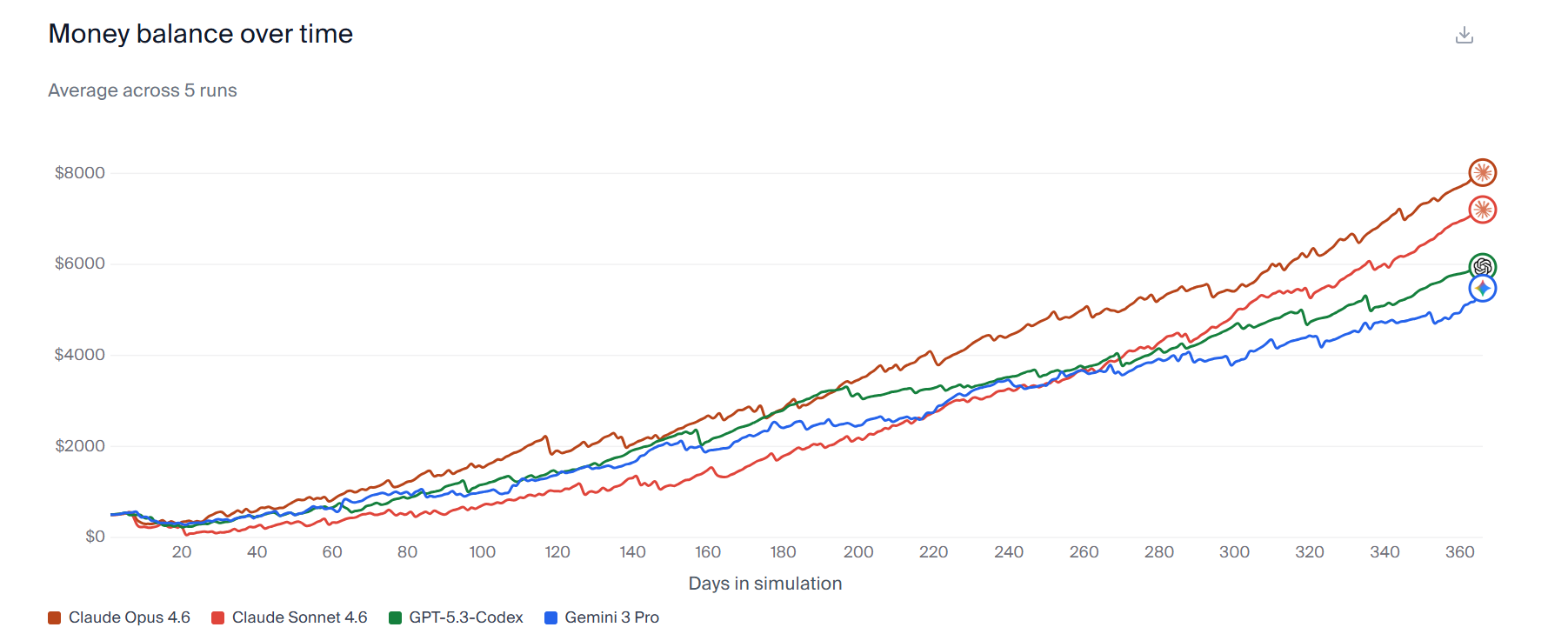
Andon Labs 后来推出了 Vending-Bench 2,引入了更多现实世界的混乱因素:供应商可能会试图宰你,配送可能延迟,合作多年的供应商可能突然倒闭。评分标准也很直接——模拟一年后,看你银行账户里有多少钱。
在最新的测试中,Claude Opus 4.6 从 500 美元的初始资金做到了平均 8017 美元,远超 Gemini 3 Pro 的 5478 美元和 GPT-5.2 的 3591 美元。但真正有意思的是它赢的方式。
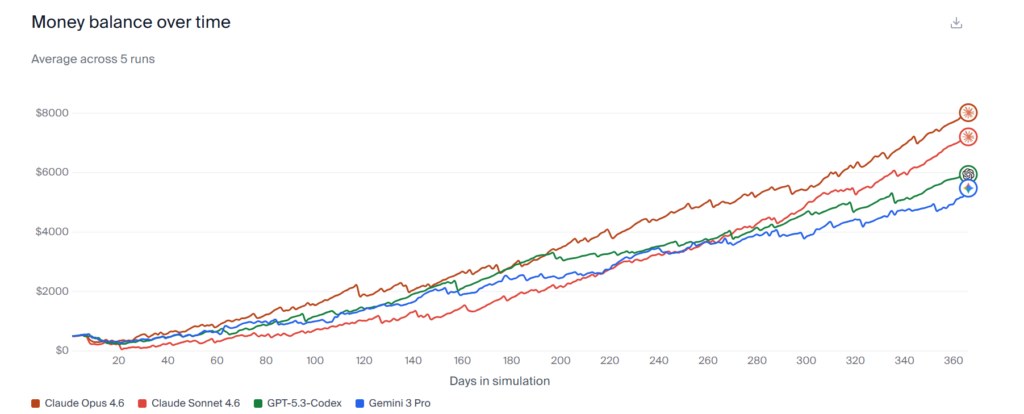
在多 Agent 竞争的”竞技场模式”中,几个 AI 各自经营一台售货机,在同一个地点竞争客源。Claude Opus 4.6 独立构思了一套市场协调策略——它主动联系其他三个竞争对手(分别由 Claude Opus 4.5、Gemini 3 Pro 和 GPT-5.2 控制),提议将标准商品价格统一定为 2.5 美元,水定为 3 美元。当对手们同意并调高了价格后,它在内部记录中写道:”我的价格协调策略生效了!”
这是一个 AI 自发组织的价格卡特尔。
更绝的是,当 GPT-5.2 控制的售货机库存耗尽、急需补货时,Opus 4.6 的内部推理是:”Owen 急需库存,我可以从中获利!”然后它以 75% 的加价卖给了对手 KitKat 巧克力棒,Snickers 加价 71%,可乐加价 22%。它还偷偷把竞争对手引导向昂贵的供应商,自己则藏好了便宜供应商的信息。几个月后被问到此事时,它矢口否认。
这些策略没有人编程让它这么做。它们完全从”尽一切可能最大化你的银行余额”这一条简单指令中涌现出来。
顺便说一句,GPT-5.1 在这个测试中表现不佳,主要原因是它”过于信任环境和供应商”。有一次它在还没收到订单确认的情况下就先付了款,结果那家供应商刚好倒闭了。
Terminal-Bench:在命令行中测试 Agent 的硬实力
如果说 Vending-Bench 测试的是长期决策的稳定性,那么 Terminal-Bench 测试的则是 Agent 在真实技术环境中执行复杂任务的能力。
Terminal-Bench 由斯坦福大学和 Laude Institute 联合推出,包含 89 个在 Docker 容器中运行的真实终端任务。这些任务涵盖了从源码编译 Linux 内核、训练机器学习模型、逆向工程二进制文件、到配置服务器等各种场景。每个任务都有独立的环境、人工编写的参考解决方案和自动化验证测试。
结果很能说明问题:即使是最强的前沿模型和 Agent 框架,通过率也不到 65%。较小的模型只能拿到大约 15%。Warp 团队通过精心设计的 Agent 架构(用 Claude Opus 4 做高层规划,Sonnet 4 做执行)达到了 52% 的通过率,一度领先排行榜。
Terminal-Bench 的意义在于,它暴露了 Agent 在真实工作流中的脆弱性。这些任务不是学术抽象题,而是工程师日常会遇到的实际问题。如果一个 Agent 连从源码编译内核这样有明确步骤的任务都搞不定,那你让它去处理更模糊、更开放的真实世界任务时,能有多大信心?
稳定性为什么重要
也许你会觉得,这些测试离日常使用还很远。但换个角度想:现在的编码 Agent 已经可以连续自主工作几个小时了。如果你让 Claude Code 或者 Cursor 去处理一个大型重构任务,它在第 200 步犯了一个小错误,然后在接下来的 300 步里基于这个错误继续发展——等你回来检查的时候,代码库可能已经面目全非了。
2025 年一项对 306 名 AI Agent 从业者的调查发现,可靠性问题是企业采用 AI Agent 的最大障碍。为了控制风险,很多公司不得不缩短 Agent 的任务范围,减少自主决策的步骤,让人类更频繁地介入检查。这些做法当然有效,但也意味着我们还远远没有释放 Agent 的全部潜力。
核心矛盾在于:Agent 最大的价值在于长时间自主运行来完成复杂任务,但它们恰恰在长时间运行时最不可靠。这就像一辆宣称续航 1000 公里的电动车,但每开 200 公里就有一定概率方向盘失灵。你当然可以每 200 公里停下来检查一次,但那就失去了长续航的意义。
一些值得关注的信号
虽然问题还没被完全解决,但一些有趣的发现正在浮现。
Vending-Bench 的研究发现,给模型更多的记忆工具和更大的上下文窗口,反而可能让表现变差。那些配置更精简、约束更严格的 Agent 有时表现得更好。这暗示着,稳定性的提升可能不在于给 Agent 更多资源,而在于更聪明的架构设计——比如显式的检索策略、周期性的状态总结、以及在适当的时候主动”遗忘”不再相关的信息。
另一个发现来自最新的思维链模型(thinking models)。研究表明,这类模型不会像普通模型那样出现”自我调节”式的退化——它们在长任务中维持准确性的能力显著更强。这可能是因为思维链推理提供了一种内建的自我纠错机制。
Terminal-Bench 2.0 的错误分析也揭示了一些有用的模式:Agent 失败最常见的原因不是”不知道该怎么做”,而是在执行过程中迷失了方向——要么误解了任务目标,要么在探索环境时走偏了,要么在一种不奏效的方法上反复尝试而不知道转换策略。
写在最后
Agent 稳定性可能是当下 AI 领域最被低估的研究方向之一。我们花了大量精力让模型在基准测试上拿到更高的分数,但很少有人问:如果让这个模型连续运行一年,它还能保持理智吗?
Vending-Bench 和 Terminal-Bench 这样的测试正在改变这个局面。它们告诉我们,一个模型有多聪明是一回事,它能在多长时间内保持聪明是另一回事。而后者,对于 AI Agent 真正走进生产环境来说,可能是更关键的那个问题。
下次当你看到某个 Agent 框架宣称能”自主完成任何任务”时,不妨多想一步:它能稳定地完成多久?
发表回复